Beta-RecSys an open source project for Building, Evaluating and Tuning Automated Recommender Systems. Beta-RecSys aims to provide a practical data toolkit for building end-to-end recommendation systems in a standardized way. It provided means for dataset preparation and splitting using common strategies, a generalized model engine for implementing recommender models using Pytorch with a lot of models available out-of-the-box, as well as a unified training, validation, tuning and testing pipeline. Furthermore, Beta-RecSys is designed to be both modular and extensible, enabling new models to be quickly added to the framework. It is deployable in a wide range of environments via pre-built docker containers and supports distributed parameter tuning using Ray.
Installation¶
Clone all the source codes from github¶
$ git clone https://github.com/beta-team/beta-recsys.git
We recommend you to use the Beta-RecSys as a non-build-in library, so that you can easily understand the structure of the Beta-RecSys framework.
Install Beta-RecSys using setup.py from github¶
- Install and record the installed files
$ git clone https://github.com/beta-team/beta-recsys.git
$ cd $project_path$
$ python setup.py install --record files.txt
- Uninstall Beta-RecSys completely
$ cd $project_path$
$ xargs rm -rf < files.txt
Install Beta-RecSys using pip¶
TBA
Introduction with Examples¶
We shortly introduce the fundamental components of Beta-RecSys through self-contained examples. At its core, Beta-RecSys provides the following main features:
Load Build-in Datasets¶
The Beta-Recsys datasets package (beta_rec.datasets) provides users a wide range of datasets for recommendation system training. With one line codes, you can obtain the split dataset based on a json config, where that process actually consists of Downloading the raw data from a public link, Decompressing the raw data, Preprocessing the raw data into a standard interaction DataFrame object, and Splitting the dataset into Training/Validation/Testing sets. More details can be found here.
from beta_rec.datasets.data_load import load_split_dataset
config = {
"dataset": "ml_100k",
"data_split": "leave_one_out",
"download": False,
"random": False,
"test_rate": 0.2,
"by_user": False,
"n_test": 10,
"n_negative": 100,
}
data_split = load_split_dataset(config)
where data_split is a tuple consists of train, valid and test sets.
- train (DataFrame): Interaction for training.
- valid (DataFrame/list(DataFrame)): List of interactions for validation.
- test (DataFrame/list(DataFrame)): List of interactions for testing.
Construct Dataloaders for training¶
The Beta-Recsys data package (beta_rec.data) provides the tools to further convert the split data sets into usable data structures (i.e. pytorch DataLoaders) (e.g. BPR (Bayesian personalized ranking) DataLoarder tensors with <user, positive_item, nagetive_item> or BCE (Binary Cross-Entropy) DataLoarder tensors <user, item, rating>), dependant on the requirements/supported features of the target model.
from beta_rec.data.base_data import BaseData
data = BaseData(data_split)
# Instance a bpr DataLoader
train_loader = data.instance_bpr_loader(
batch_size=512,
device="cpu",
)
# Instance a bce DataLoader
train_loader = data.instance_bce_loader(
batch_size=512,
device="cpu",
)
Run Matrix Factorization model¶
Beta-Recsys provides 9 recommendation models that can be used out-of-the-box. For each model, we provide a default config/hyperparamter setting in the format if JOSN. Note that these models also accept hyperparamters from command lines.
Default config (configs/)¶
{
"system": {
"root_dir": "../",
"log_dir": "logs/",
"result_dir": "results/",
"process_dir": "processes/",
"checkpoint_dir": "checkpoints/",
"dataset_dir": "datasets/",
"run_dir": "runs/",
"tune_dir": "tune_results/",
"device": "gpu",
"seed": 2020,
"metrics": ["ndcg", "precision", "recall", "map"],
"k": [5,10,20],
"valid_metric": "ndcg",
"valid_k": 10,
"result_file": "mf_result.csv"
},
"dataset": {
"dataset": "ml_100k",
"data_split": "leave_one_out",
"download": false,
"random": false,
"test_rate": 0.2,
"by_user": false,
"n_test": 10,
"n_negative": 100,
"result_col": ["dataset","data_split","test_rate","n_negative"]
},
"model": {
"model": "MF",
"config_id": "default",
"emb_dim": 64,
"num_negative": 4,
"batch_size": 400,
"batch_eval": true,
"dropout": 0.0,
"optimizer": "adam",
"loss": "bpr",
"lr": 0.05,
"reg": 0.001,
"max_epoch": 20,
"save_name": "mf.model",
"result_col": ["model","emb_dim","batch_size","dropout","optimizer","loss","lr","reg"]
}
}
examples/train_mf.py¶
python train_mf.py
Tune hyper-parameters for the Matrix Factorization model¶
To support easier and faster hyperparameter tuning for each model, we also integrate the Ray framework, which is a Python library for model training at scale. This enables the distribution of model training/tuning across multiple gpus and/or compute nodes.
{
"tunable": [
{"name": "loss", "type": "choice", "values": ["bce", "bpr"]}
]
}
Then run train_mf.py with parameter ‘–tune’
python train_mf.py --tune True
Building your own model with the framework in 3 steps¶
An example of the Matrix Factorization
1. create mf.py in the models folder¶
import torch
import torch.nn as nn
from torch.nn import Parameter
from beta_rec.models.torch_engine import ModelEngine
from beta_rec.utils.common_util import print_dict_as_table, timeit
class MF(torch.nn.Module):
"""A pytorch Module for Matrix Factorization."""
def __init__(self, config):
"""Initialize MF Class."""
super(MF, self).__init__()
self.config = config
self.device = self.config["device_str"]
self.stddev = self.config["stddev"] if "stddev" in self.config else 0.1
self.n_users = self.config["n_users"]
self.n_items = self.config["n_items"]
self.emb_dim = self.config["emb_dim"]
self.user_emb = nn.Embedding(self.n_users, self.emb_dim)
self.item_emb = nn.Embedding(self.n_items, self.emb_dim)
self.user_bias = nn.Embedding(self.n_users, 1)
self.item_bias = nn.Embedding(self.n_items, 1)
self.global_bias = Parameter(torch.zeros(1))
self.user_bias.weight.data.fill_(0.0)
self.item_bias.weight.data.fill_(0.0)
self.global_bias.data.fill_(0.0)
nn.init.normal_(self.user_emb.weight, 0, self.stddev)
nn.init.normal_(self.item_emb.weight, 0, self.stddev)
def forward(self, batch_data):
"""Trian the model.
Args:
batch_data: tuple consists of (users, pos_items, neg_items), which must be LongTensor.
"""
users, items = batch_data
u_emb = self.user_emb(users)
u_bias = self.user_bias(users)
i_emb = self.item_emb(items)
i_bias = self.item_bias(items)
scores = torch.sigmoid(
torch.sum(torch.mul(u_emb, i_emb).squeeze(), dim=1)
+ u_bias.squeeze()
+ i_bias.squeeze()
+ self.global_bias
)
regularizer = (
(u_emb ** 2).sum()
+ (i_emb ** 2).sum()
+ (u_bias ** 2).sum()
+ (i_bias ** 2).sum()
) / u_emb.size()[0]
return scores, regularizer
def predict(self, users, items):
"""Predcit result with the model.
Args:
users (int, or list of int): user id(s).
items (int, or list of int): item id(s).
Return:
scores (int, or list of int): predicted scores of these user-item pairs.
"""
users_t = torch.LongTensor(users).to(self.device)
items_t = torch.LongTensor(items).to(self.device)
with torch.no_grad():
scores, _ = self.forward((users_t, items_t))
return scores
class MFEngine(ModelEngine):
"""MFEngine Class."""
def __init__(self, config):
"""Initialize MFEngine Class."""
self.config = config
print_dict_as_table(config["model"], tag="MF model config")
self.model = MF(config["model"])
self.reg = (
config["model"]["reg"] if "reg" in config else 0.0
) # the regularization coefficient.
self.batch_size = config["model"]["batch_size"]
super(MFEngine, self).__init__(config)
self.model.to(self.device)
self.loss = (
self.config["model"]["loss"] if "loss" in self.config["model"] else "bpr"
)
print(f"using {self.loss} loss...")
def train_single_batch(self, batch_data):
"""Train a single batch.
Args:
batch_data (list): batch users, positive items and negative items.
Return:
loss (float): batch loss.
"""
assert hasattr(self, "model"), "Please specify the exact model !"
self.optimizer.zero_grad()
if self.loss == "bpr":
users, pos_items, neg_items = batch_data
pos_scores, pos_regularizer = self.model.forward((users, pos_items))
neg_scores, neg_regularizer = self.model.forward((users, neg_items))
loss = self.bpr_loss(pos_scores, neg_scores)
regularizer = pos_regularizer + neg_regularizer
elif self.loss == "bce":
users, items, ratings = batch_data
scores, regularizer = self.model.forward((users, items))
loss = self.bce_loss(scores, ratings)
else:
raise RuntimeError(
f"Unsupported loss type {self.loss}, try other options: 'bpr' or 'bce'"
)
batch_loss = loss + self.reg * regularizer
batch_loss.backward()
self.optimizer.step()
return loss.item(), regularizer.item()
@timeit
def train_an_epoch(self, train_loader, epoch_id):
"""Train a epoch, generate batch_data from data_loader, and call train_single_batch.
Args:
train_loader (DataLoader):
epoch_id (int): the number of epoch.
"""
assert hasattr(self, "model"), "Please specify the exact model !"
self.model.train()
total_loss = 0.0
regularizer = 0.0
for batch_data in train_loader:
loss, reg = self.train_single_batch(batch_data)
total_loss += loss
regularizer += reg
print(f"[Training Epoch {epoch_id}], Loss {loss}, Regularizer {regularizer}")
self.writer.add_scalar("model/loss", total_loss, epoch_id)
self.writer.add_scalar("model/regularizer", regularizer, epoch_id)
In the mf.py, you may want to add two classes, class NEWMODEL (all in capital) and class NEWMODELEngine. The NEWMODEL calss should include all necessary initialisations (e.g. embeddings initialisation), forward function to calculate all intermedinate variables and predict function to calculate predicted scores for each (user, item) pair. In the NEWMODELEngine, first you need load the training data and corresponding configs. Then you use two functions train_an_epoch and train_single_batch to feed data to the NEWMODEL class. A classic train_loader, which can sample user, positive items and negative items is already included in our project. You can see much efforts by loading existing functions.
2. create mf_default.json in the configs folder¶
You also need a .json file, which includes all parameters for your models. This config file bring much convenience when you want to run a model several times with different parameters. Parameters can be changed from the command line. Below is a exmaple of a config file for the matrix factorisation model.
{
"system": {
"root_dir": "../",
"log_dir": "logs/",
"result_dir": "results/",
"process_dir": "processes/",
"checkpoint_dir": "checkpoints/",
"dataset_dir": "datasets/",
"run_dir": "runs/",
"tune_dir": "tune_results/",
"device": "gpu",
"seed": 2020,
"metrics": ["ndcg", "precision", "recall", "map"],
"k": [5,10,20],
"valid_metric": "ndcg",
"valid_k": 10,
"result_file": "mf_result.csv"
},
"dataset": {
"dataset": "ml_100k",
"data_split": "leave_one_out",
"download": false,
"random": false,
"test_rate": 0.2,
"by_user": false,
"n_test": 10,
"n_negative": 100,
"result_col": ["dataset","data_split","test_rate","n_negative"]
},
"model": {
"model": "MF",
"config_id": "default",
"emb_dim": 64,
"num_negative": 4,
"batch_size": 400,
"batch_eval": true,
"dropout": 0.0,
"optimizer": "adam",
"loss": "bpr",
"lr": 0.05,
"reg": 0.001,
"max_epoch": 20,
"save_name": "mf.model",
"result_col": ["model","emb_dim","batch_size","dropout","optimizer","loss","lr","reg"]
},
"tunable": [
{"name": "loss", "type": "choice", "values": ["bce", "bpr"]}
]
}
3. create new_example.py in the examples folder¶
import argparse
import os
import sys
import time
sys.path.append("../")
from ray import tune
from beta_rec.core.train_engine import TrainEngine
from beta_rec.models.mf import MFEngine
from beta_rec.utils.common_util import DictToObject, str2bool
from beta_rec.utils.monitor import Monitor
def parse_args():
"""Parse args from command line.
Returns:
args object.
"""
parser = argparse.ArgumentParser(description="Run MF..")
parser.add_argument(
"--config_file",
nargs="?",
type=str,
default="../configs/mf_default.json",
help="Specify the config file name. Only accept a file from ../configs/",
)
parser.add_argument(
"--root_dir", nargs="?", type=str, help="Root path of the project",
)
# If the following settings are specified with command line,
# These settings will used to update the parameters received from the config file.
parser.add_argument(
"--dataset",
nargs="?",
type=str,
help="Options are: tafeng, dunnhunmby and instacart",
)
parser.add_argument(
"--data_split",
nargs="?",
type=str,
help="Options are: leave_one_out and temporal",
)
parser.add_argument(
"--tune", nargs="?", type=str2bool, help="Tun parameter",
)
parser.add_argument(
"--device", nargs="?", type=str, help="Device",
)
parser.add_argument(
"--loss", nargs="?", type=str, help="loss: bpr or bce",
)
parser.add_argument(
"--remark", nargs="?", type=str, help="remark",
)
parser.add_argument(
"--emb_dim", nargs="?", type=int, help="Dimension of the embedding."
)
parser.add_argument("--lr", nargs="?", type=float, help="Initial learning rate.")
parser.add_argument("--reg", nargs="?", type=float, help="regularization.")
parser.add_argument("--max_epoch", nargs="?", type=int, help="Number of max epoch.")
parser.add_argument(
"--batch_size", nargs="?", type=int, help="Batch size for training."
)
return parser.parse_args()
class MF_train(TrainEngine):
"""MF_train Class."""
def __init__(self, args):
"""Initialize MF_train Class."""
print(args)
super(MF_train, self).__init__(args)
def train(self):
"""Train the model."""
self.load_dataset()
self.gpu_id, self.config["device_str"] = self.get_device()
""" Main training navigator
Returns:
"""
# Train NeuMF without pre-train
self.monitor = Monitor(
log_dir=self.config["system"]["run_dir"], delay=1, gpu_id=self.gpu_id
)
if self.config["model"]["loss"] == "bpr":
train_loader = self.data.instance_bpr_loader(
batch_size=self.config["model"]["batch_size"],
device=self.config["model"]["device_str"],
)
elif self.config["model"]["loss"] == "bce":
train_loader = self.data.instance_bce_loader(
num_negative=self.config["model"]["num_negative"],
batch_size=self.config["model"]["batch_size"],
device=self.config["model"]["device_str"],
)
else:
raise ValueError(
f"Unsupported loss type {self.config['loss']}, try other options: 'bpr' or 'bce'"
)
self.engine = MFEngine(self.config)
self.model_save_dir = os.path.join(
self.config["system"]["model_save_dir"], self.config["model"]["save_name"]
)
self._train(self.engine, train_loader, self.model_save_dir)
self.config["run_time"] = self.monitor.stop()
return self.eval_engine.best_valid_performance
def tune_train(config):
"""Train the model with a hypyer-parameter tuner (ray).
Args:
config (dict): All the parameters for the model.
"""
train_engine = MF_train(DictToObject(config))
best_performance = train_engine.train()
train_engine.test()
while train_engine.eval_engine.n_worker > 0:
time.sleep(20)
tune.track.log(valid_metric=best_performance)
if __name__ == "__main__":
args = parse_args()
if args.tune:
train_engine = MF_train(args)
train_engine.tune(tune_train)
else:
train_engine = MF_train(args)
train_engine.train()
train_engine.test()
In this new_example.py file, you need import the TrainEngine from core and the NEWMODELEngine from the new_model.py. The parse_args function will help you to load parameters from the command line and the config file. You can simply run your model once or you may want to apply a grid search by the Tune module. You should define all tunable parameters in your config file.
Overview of the Framework¶

Prepare Data¶
To make the workflow efficient, we implement two key reusable components for preparing training data for different recommender models. The BaseDataset component provides unified interfaces for processing the raw dataset into interactions and splitting it using common strategies (e.g. leave-one-out, random split or temporal split) into training/validation/testing sets. Meanwhile the BaseData provides the tools to further convert the resultant data sets into usable data structures (e.g. tensors with < 𝑢𝑠𝑒𝑟,𝑖𝑡𝑒𝑚, 𝑟𝑎𝑡𝑖𝑛𝑔 > or < 𝑢𝑠𝑒𝑟, 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒_𝑖𝑡𝑒𝑚, 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒_𝑖𝑡𝑒𝑚(𝑠) >), dependant on the requirements/supported features of the target model. Out-of-the-box we support a number of commonly used datasets, including Movielens_100k, Movielens_1m, Movielens_25m, LastFM.
Build Models¶
Our project provides a model engine (i.e. represented by the class ModelEngine) for conveniently building a pytorch recommender model in a unified manner. In particular, it provides a unified implementation for saving and loading models, specifying the compute device, optimizer and loss (e.g. BPR loss or BCE loss) to use during training. Out-of-the-box, 9 recommendation models are provided, including classic baselines like MF, as well as more advanced neural models such as NCF, NGCF and Triple2vec.
Train & Tune Models¶
The TrainEngine component provides unified mechanisms to manage the end-to-end training process. This encompasses: loading the configuration; loading the data; training each epoch; calculating validation performance; checkpointing models; testing early stopping criteria; and calculating the final test performance. The TrainEngine also supports monitoring/visualizing the training progress in real time, including resource consumption and training metrics (such as the training loss and evaluation performance on both the validation and testing sets) of a deployed model via Tensorboard. It can also expose these real-time metrics to a Prometheus time-series data store via an in-built Prometheus exporter, enabling programmatic access to the training state. To support easier and faster hyperparameter tuning for each model, we also integrate the Ray framework 8 , which is a Python library for model training at scale. This enables the distribution of model training/tuning across multiple gpus and/or compute nodes.
Evaluate Performance¶
Three categories of commonly used evaluation metrics for recommender system are included in this platform, namely rating metrics, ranking metrics and classification metrics. For rating metrics, we use Root Mean Square Error (RMSE), R Squared (𝑅2) and Mean Average Error (MAE) to measure the effectiveness. For ranking metrics, we included Recall, Precision, Normalized Discounted Cumulative Gain (NDCG) and Mean Average Precision (MAP) to measure performance of ranking lists. Model evaluation using build-in classification metrics like Area-Under-Curve (AUC) and Logistic loss are also supported. For detailed definitions of these metrics, readers are referred to [1]. To accelerate the evaluation process, the metric implementations are multi-threaded.
[1] Asela Gunawardana and Guy Shani. 2009. A survey of accuracy evaluation metrics of recommendation tasks. Journal of Machine Learning Research 10, Dec (2009), 2935–2962.
DataSets¶
Introduction¶
Beta-Recsys provides users a wide range of datasets for recommendation system training. For convenience, we preprocess a number of datasets for you to train, getting you rid of splitting them on you local machine. Also this framework provides users a set of useful interfaces for data split.
Usage¶
The following codes can automatically download the Movielens_100k dataset, and split it using the leave-one-out splitting strategy.
from beta_rec.datasets.movielens import Movielens_100k
dataset = Movielens_100k()
split_dataset = dataset.load_leave_one_out()
To clean the dataset by filtering before splitting, you can use the filtering parameters. E.g., to filter out users that have less then 30 items and items that have less then 15 records, you can run:
dataset = Movielens_100k(min_u_c=15, min_i_c=30)
with these filtering parameters showing as follows:
min_u_c: filter the items that were purchased by less than min_u_c users.
(default: :obj:`0`)
min_i_c: filter the users that have purchased by less than min_i_c items.
(default: :obj:`3`)
min_o_c: filter the users that have purchased by less than min_o_c orders.
(default: :obj:`0`)
By default, the testing set will sample 100 negative items to reduce the evaluation cost. To reduce the bias of certain negative items, each splitting strategy will generate 10 different validation and testing sets. You can also specify these parameters:
split_dataset = dataset.load_leave_one_out(n_test=15,n_negative=200)
If you want to use the data splits generate by our Beta team, you can specify the download parameter.
from beta_rec.datasets.movielens import Movielens_100k
dataset = Movielens_100k()
split_dataset = dataset.load_leave_one_out(download=True)
For some very large datasets, generating negative items can be time-costly. This feature can greatly reduce some repeated work, and provide a benchmarking.
Note: 25, Oct. 2020. Now the preprocessed splits of each dataset are a bit out-of-date, we will regenerate a new version as soon as possible.
Dataset Statistics¶
Here we present some basic staticstics for the datasets in our framework.
| Dataset | Interactions | Baskets | Temporal |
|---|---|---|---|
| MovieLens-100K | ✔️ | ✖️ | ✔️ |
| MovieLens-1M | ✔️ | ✖️ | ✔️ |
| MovieLens-25M | ✔️ | ✖️ | ✔️ |
| Last.FM | ✔️ | ✖️ | ✖️ |
| Epinions | ✔️ | ✖️ | ✖️ |
| Tafeng | ✔️ | ✖️ | ✔️ |
| Dunnhumby | ✔️ | ✔️ | ✔️ |
| Instacart | ✔️ | ✖️ | ✔️ |
| citeulike-a | ✔️ | ✖️ | ✖️ |
| citeulike-t | ✔️ | ✖️ | ✖️ |
| HetRec MoiveLens | ✔️ | ✖️ | ✔️ |
| HetRec Delicious | ✔️ | ✔️ | ✖️ |
| HetRec LastFM | ✔️ | ✔️ | ✔️ |
| Yelp | ✔️ | ✖️ | ✔️ |
| Gowalla | ✔️ | ✖️ | ✔️ |
| Yoochoose | ✔️ | ✖️ | ✔️ |
| Diginetica | ✔️ | ✖️ | ✔️ |
| Taobao | ✔️ | ✖️ | ✔️ |
| Ali-mobile | ✔️ | ✖️ | ✔️ |
| Retailrocket | ✔️ | ✖️ | ✔️ |
| Amazon Reviews | ✔️ |
Because some split methods require a specific features, like random_basket expect the dataset has a Basket column. Here we list all the split methods for each dataset.
The prerequisite for each split methods are:
leave_one_out: noneleave_one_basket: require a Basket column in datasetrandom: nonerandom_basket: require a Basket column in datasettemporal: require a Timestamp(Temporal) column in datasettemporal_basket: require a Timestamp(Temporal) and a Basket column in dataset
| Dataset | leave_one_out | leave_one_basket | random | random_basket | temporal | temporal_basket |
|---|---|---|---|---|---|---|
| MovieLens-100K | ✔️ | ✖️ | ✔️ | ✖️ | ✔️ | ✖️ |
| MovieLens-1M | ✔️ | ✖️ | ✔️ | ✖️ | ✔️ | ✖️ |
| MovieLens-25M | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | |
| Last.FM | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | ✖️ |
| Epinions | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | ✖️ |
| Tafeng | ✔️ | ✖️ | ✔️ | ✖️ | ✔️ | ✖️ |
| Dunnhumby | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Instacart | ✔️ | ✖️ | ✔️ | ✖️ | ✔️ | ✖️ |
| citeulike-a | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | ✖️ |
| citeulike-t | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | ✖️ |
| HetRec MoiveLens | ✔️ | ✖️ | ✔️ | ✖️ | ✔️ | ✖️ |
| HetRec Delicious | ✔️ | ✔️ | ✔️ | ✖️ | ✖️ | ✖️ |
| HetRec LastFM | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Yelp | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | |
| Gowalla | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | |
| Yoochoose | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | |
| Diginetica | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | |
| Taobao | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | |
| Ali-mobile | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | |
| Retailrocket | ✔️ | ✖️ | ✔️ | ✖️ | ✖️ | |
| Amazon Reviews |
Also, we provide some information about the dataset content such as the number of items, users and so on. This may give you a brief view of the dataset.
| Dataset | #Interactions | #User | #Item | #Rating | #Timestamp |
|---|---|---|---|---|---|
| MovieLens-100K | 100,000 | 943 | 1,682 | 5 | 49,282 |
| MovieLens-1M | 1,000,209 | 6,040 | 3,706 | 5 | 458,455 |
| MovieLens-25M | 25,000,095 | 162,541 | 59,047 | 10 | 20,115,267 |
| Last.FM | 92,834 | 1,892 | 17,632 | 5,436 | 1 |
| Epinions | 664,825 | 40,163 | 139,738 | 5 | 1 |
| Tafeng | 464118 | 9238 | 7973 | 1 | 464118 |
| Dunnhumby | 2595732 | 2500 | 92339 | 1 | 2595732 |
| Instacart | 33,819,106 | 206,209 | 49,685 | 1 | 3,346,083 |
| citeulike-a | 204,986 | 240 | 16,980 | 1 | 1 |
| citeulike-t | 134,860 | 216 | 25,584 | 1 | 1 |
| HetRec MoiveLens | 855,598 | 2,113 | 10,109 | 10 | 809,328 |
| HetRec Delicious | 437,593 | 1,867 | 69,223 | 1 | 104,093 |
| HetRec LastFM | 186,479 | 1,892 | 12,523 | 1 | 9,749 |
| Yelp | 8,021,122 | 1,968,703 | 209,393 | 5 | 7,853,102 |
| Gowalla | 6,442,892 | 107,092 | 1,280,969 | 1 | 5,561,957 |
| Yoochoose | 1,150,753 | 509,696 | 735 | 1 | 19,949 |
| Diginetica | 1,235,380 | 310,324 | 122,993 | 1 | 152 |
| Taobao | 3,835,331 | 37,376 | 930,607 | 1 | 698,889 |
| Ali-mobile | 12,256,906 | 10,000 | 2,876,947 | 1 | 1 |
| Retailrocket | 2,756,101 | 1,407,58 | 235,061 | 1 | 2,749,921 |
| Amazon Reviews -- Amazon Instant Video | 583,933 | 426,922 | 23,965 | 5 | 3,027 |
| Amazon Reviews -- Musical Instruments | 500,176 | 339,231 | 83,046 | 5 | 5,339 |
| Amazon Reviews -- Digital Music | 836,006 | 478,235 | 266,414 | 5 | 5,941 |
| Amazon Reviews -- Baby | 915,446 | 531,890 | 64,426 | 5 | 4,869 |
| Amazon Reviews -- Grocery and Gourmet Food | 1,297,156 | 768,438 | 166,049 | 5 | 3,831 |
| Amazon Reviews -- Patio, Lawn and Garden | 993,490 | 714,791 | 105,984 | 5 | 4,929 |
| Amazon Reviews -- Automotive | 1,373,768 | 851,418 | 320,112 | 5 | 3,704 |
| Amazon Reviews -- Pet Supplies | 1,235,316 | 740,985 | 103,288 | 5 | 3,900 |
| Amazon Reviews -- Cell Phones and Accessories | 3,447,249 | 2,261,045 | 319,678 | 5 | 4,724 |
| Amazon Reviews -- Health and Personal Care | 2,982,326 | 1,851,132 | 252,331 | 5 | 4,733 |
| Amazon Reviews -- Toys and Games | 2,252,771 | 1,342,911 | 327,698 | 5 | 5,151 |
| Amazon Reviews -- Video Games | 1,324,753 | 826,767 | 50,210 | 5 | 5,396 |
| Amazon Reviews -- Tools and Home Improvement | 1,926,047 | 1,212,468 | 260,659 | 5 | 5,366 |
| Amazon Reviews -- Beauty | 2,023,070 | 1,210,271 | 249,274 | 5 | 4,231 |
| Amazon Reviews -- Apps for Android | 2,638,173 | 1,323,884 | 61,275 | 5 | 1,283 |
| Amazon Reviews -- Office Products | 1,243,186 | 909,314 | 130,006 | 5 | 5,400 |
| Amazon Reviews -- Sports And Outdoors | 3,268,695 | 1,990,521 | 478,898 | 5 | 4,786 |
| Amazon Reviews -- Kindle Store | 3205467 | 1,406,890 | 1,406,890 | 5 | 3,328 |
| Amazon Reviews -- Home And Kitchen | 4,253,926 | 2,511,610 | 410,243 | 5 | 5,202 |
| Amazon Reviews -- Clothing Shoes And Jewelry | 5,748,920 | 3,117,268 | 1,136,004 | 5 | 4,209 |
| Amazon Reviews -- CDs And Vinyl | 3,749,004 | 1,578,597 | 486,360 | 5 | 6,041 |
| Amazon Reviews -- Movies And TV | 4,607,047 | 2,088,620 | 200,941 | 5 | 6,004 |
| Amazon Reviews -- Electronics | 7,824,482 | 4,201,696 | 476,002 | 5 | 5,489 |
| Amazon Reviews -- Books | 22,507,155 | 8,026,324 | 2,330,066 | 5 | 6,296 |
Dataset Usage¶
Download Data¶
Beta-Recsys provides download interface for users to download different dataset. Here is an example:
import sys
import os
sys.path.append(os.path.abspath('.'))
from beta_rec.datasets.movielens import Movielens_1m
movielens_1m = Movielens_1m()
movielens_1m.download()
However, not every dataset could be downloaded directly with our framework. For some datasets, you will still have to download them manually. You are supposed to follow our tips to download and put the dataset in the correct folder in order to be detected by our framework.
Load Data¶
Downloading and preprocessing giant datasets may be a disturbing things, and in order to deal with this issue, we have preprocessed a wide range of datasets and stored the processed data in our remote server. Users can access them easily by using our load function.
import sys
import os
sys.path.append(os.path.abspath('.'))
from beta_rec.datasets.movielens import Movielens_1m
movielens_1m = Movielens_1m()
movielens_1m.load_leave_one_out()
movielens_1m.load_random_split()
Due to storage limitation, we only store a copy of split data with default parameters. If you want a custom split, you’ll still have to split them on you local machine.
Make Data¶
Users can simply ignore these functions because when you use custom parameters in load functions, it will automatically call make functions. So you don’t need to care about this functions. We strongly recommend you to use load function directly in most of you time.
Data Split¶
For users who are willing to split some datasets that are not covered by our framework, we still provide various methods to make it easy to split huge data, without caring the implementation details. There are 6 main methods for users to split data.
random_split¶
This method splits data into random train and test subsets.
This method will first shuffle all the data and then select a portion of records based on the given test_rate randomly.
random_basket_split¶
This method will select a portion of baskets(one basket may cover more than one record) based on the given test_rate randomly.
leave_one_out¶
This method will first rank all the records by time (if a timestamp column is provided), and then select the last record.
leave_one_basket¶
This method provides train/test indices to split data in train/test sets. Each sample is used once as a test set while the remaining samples form the training set.
This method will first rank all the records by time (if a timestamp column is provided), and then select the last basket.
Due to the high number of test sets this method can be very costly.
temporal_split¶
This method will first rank all the records by time (if a timestamp column is provided), and then select the last portion of records.
This splitting approach is for evaluating how well a model performs on segments drawn from the same time series but excluded from the training set.
temporal_basket_split¶
This method will first rank all the records by time (if a timestamp column is provided), and then select the last portion of baskets.
Disclaimer on Datasets¶
This is a utility library that downloads and prepares public datasets. We do not host or distribute these datasets, vouch for their quality or fairness, or claim that you have license to use the dataset. It is your responsibility to determine whether you have permission to use the dataset under the dataset’s license.
If you’re a dataset owner and wish to update any part of it (description, citation, etc.), or do not want your dataset to be included in this library, please get in touch through a GitHub issue. Thanks for your contribution to the RecSys community!
More¶
For any quesitons, please tell us by creating an issue or contact us by sending an email to recsys.beta@gmail.com. We will try to respond it as soon as possible.
DataLoaders¶
Beta-recsys provides reusable components (i.e. DataLoaders), which further process the generated train/valid/test data sets by leveraging the BaseDataset component. In particular, given a specific task to address and the implementation of the corresponding model, DataLoaders convert these train/valid/test datasets into usable data structures (e.g. tensors with < 𝑢𝑠𝑒𝑟,𝑖𝑡𝑒𝑚, 𝑟𝑎𝑡𝑖𝑛𝑔 > or < 𝑢𝑠𝑒𝑟, 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒_𝑖𝑡𝑒𝑚, 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒_𝑖𝑡𝑒𝑚(𝑠) >). Therefore, DataLoaders allow users to load data and data-related features to fulfil distinct requirements.
In this note, we use the grocery data as an example to describe the workflow of DataLoaders.
BaseData¶
First, BaseData is the base class in the DataLoaders workflow. The BaseData provides various general functions to model the input data (namely the generated train/valid/test data). Currently, the BaseData includes the following functions:
_binarize(bin_thld): It converts the ground truth (e.g. explicit user ratings) into binarize data with given threshold bin_thld._normalize(): It applies the min-max normalisation to the ground truth data._re_index(): It reindexes the identification of users and items to avoid conflictions or user/item indexing error after applying user/item filtering approaches._intersect(): It intersects validation and test datasets with the training dataset to remove users or items that only exist in the training dataset but not in the validation and testing dataset.
Additionally, BaseData also includes common types of data loader instances to enable fast implementation of loading data for a recommendation model. It has the following instances at this stage:
instance_bce_loader(): It structured data into < 𝑢𝑠𝑒𝑟,𝑖𝑡𝑒𝑚, 𝑟𝑎𝑡𝑖𝑛𝑔 > to address pointwise tasks. For example, the binary cross-entropy loss can be applied to learn the pointwise prediction results.instance_bpr_loader(): It structured data into < 𝑢𝑠𝑒𝑟, 𝑝𝑜𝑠𝑖𝑡𝑖𝑣𝑒_𝑖𝑡𝑒𝑚, 𝑛𝑒𝑔𝑎𝑡𝑖𝑣𝑒_𝑖𝑡𝑒𝑚(𝑠) > for a pair-wise comparison usage (e.g. Bayesian Personalised Ranking).
TaskData¶
After initialising the BaseData, for different tasks, a model might require additional feature data or data loaded in different structures. Furthermore, users can add extra functions to request data for customised usages.
For example, the GroceryData class inherits the BaseData and Auxiliary classes to enable the basic data loading requirement and the usage of auxiliary data. It also has another two functions, sample_triple_time and sample_triple, to sample data under indicated criteria.
Additional DataLoaders¶
Beta-recsys also enables users to add customised DataLoaders for various usages. However, instead of updating the BaseData class, users can add extra DataLoader classes in the data_loaders.py file to organise the code.
More¶
For any quesitons, please tell us by creating an issue or contact us by sending an email to recsys.beta@gmail.com. We will try to respond it as soon as possible.
Models¶
MF¶
Matrix Factorization (MF) used in recommender systems decomposes user-item interaction matrix  into the product of two lower dimensionality rectangular matrices
into the product of two lower dimensionality rectangular matrices  and
and  , making the product of
, making the product of  close to the real
close to the real  matrix as much as possible. Matrix Factorization is the mainstream algorithm based on implicit factors.
matrix as much as possible. Matrix Factorization is the mainstream algorithm based on implicit factors.
GMF¶
Generalized Matrix Factorization (GMF) is the weighted output of dot product of the embedding vectors of user and item after activation function. Let  denote active function,
denote active function,  denote the embedding vector of user,
denote the embedding vector of user,  denote the embedding vector of item, $h$ denote the weights of linear function, then the result of GMF is :
denote the embedding vector of item, $h$ denote the weights of linear function, then the result of GMF is :

GMF usually deals with the problem of linear interaction.
MLP¶
Multi-Layer Perceptrons (MLPs) is a class of feedforward artificial neural network, consisting at least an input layer, a hidden layer and an output layer. Assume a MLP model has  layers,
layers,  denotes the weight matrix of
denotes the weight matrix of  layer,
layer,  denotes the bias of MLPs,
denotes the bias of MLPs,  denotes the activate function of layer, then the result of MLPs is :
denotes the activate function of layer, then the result of MLPs is :

 denotes the concatenation of embedding vectors of user and item. MLPs usually deals with the problem of non-linear interaction.
denotes the concatenation of embedding vectors of user and item. MLPs usually deals with the problem of non-linear interaction.
NCF¶
Neural Collaborative Filtering (MCF) is based on GMF and MLP. Let  denote the result vector of GMF,
denote the result vector of GMF,  denote the result vector of MLP, then the result of NCF is :
denote the result vector of MLP, then the result of NCF is :

where  denotes the weights of NCF.
denotes the weights of NCF.
NGCF¶
Neural Graph Collaborative Filtering (NGCF) is a recommender systems framework that exploits the user-item graph structure by propagating embeddings on it, which leads to the expressive modeling of high-order connectivity in user-item graph, effectively injecting the collaborative signal into the embedding process in an explicit manner. You can find more details in the origin NGCF-paper.
LIGHT_GCN¶
LightGCN is a model containing only the most essential component in Graph Convolution Network for collaborative filtering, it learns user and item embeddings by linearly propagating them on the user-item interaction graph, and uses the weighted sum of the embeddings learned at all players as the final embedding. You can find more details in the origin LIGHT_GCN-paper.
CMN¶
Collaborative Memory Network (CMN) is a deep architecture to unify the two classes of Collaborative Filtering models capitalizing on the strengths of the global structure of latent factor model and local neighborhood-based structure in a nonlinear fashion. You can find more details in the origin CMN-paper.
Triple2Vec¶
Triple2Vec A model that learns user and item embeddings by training a Skip-gram model based on sampled triples. Triple2vec uses the Skip-gram model to recover the sampled triples (i.e. a user and two items occurring in the same basket of that user) from the users’ baskets for product representations and purchase prediction. Triple2Vec-paper.
VBCAR¶
Variational Bayesian Context-aware Representation for Grocery Recommendation (VBCAR) is a novel variational Bayesian model that learns the user and item latent vectors by leveraging basket context information from past user-item interactions. You can find more details in the origin VBCAR-paper.
NARM¶
Neural Attentive Session Based Recommendation Model (NARM) is a neural networks framework that tackle problem that not only considers the user’s sequential behavior in the current session but also emphasizing the user’s main purpose in the current session. You can find more details in the origin NARM-paper.
PAIRWISE_GMF¶
Evaluation Metrics¶
RMSE¶
Root Mean Square Error (RMSE) is a frequently used measure of the differences between values (sample or population values) predicted by a model or an estimator and values observed, and its formula is given as follows:

where  denotes the value predicted by a model,
denotes the value predicted by a model,  denotes the observed values.
denotes the observed values.
MAE¶
Mean Absolute Error (MAE) is a measure of errors between paired observations expressing the same phenomenon.

where denotes the value predicted by a model, denotes the observed value.
R-squared¶
R-Squared ( ) also known as coefficient of determination, is usually used in the context of statistical models whose main purpose is either the prediction of future outcomes or the testing of hypotheses, on the basis of other related information. is usually determined by the total sum of squares (denoted as
) also known as coefficient of determination, is usually used in the context of statistical models whose main purpose is either the prediction of future outcomes or the testing of hypotheses, on the basis of other related information. is usually determined by the total sum of squares (denoted as  ), and the residual sum of squares (denoted as
), and the residual sum of squares (denoted as  ), and its formula is as follows:
), and its formula is as follows:

is calculated as follows:

where denotes the observed value,  denotes the average values of all observed values.
denotes the average values of all observed values.
is calculated as follows:

where denotes the observed value, denotes the predicted value.
Explained Variance¶
Explained Variance is used to measure the discrepancy between a model and actual data. Its formula is given as follows:

where denotes the observed value, denotes the predicted value.
AUC¶
Area Under Curve (AUC) usually used in classification analysis in order to determine which of the used models predicts the classes best. In recommender systems, AUC is usually used to metric for implicit feedback type recommender, where rating is binary and prediction is float number ranging from 0 to 1. For more details, you can refer to Wikipedia.
LogLoss¶
Log Loss also known as Cross-Entropy Loss, its discrete formal is given as follows:
![LogLoss=-\frac{1}{N}\sum_{n=1}^{N}[y_n\log\hat{y_n}+(1-y_n)\log(1-\hat{y_n})]](_images/math/623aaa79609ddb7edb3b74f5fda810a3e28d6778.png)
where  represents whether the predicted result is positive.
represents whether the predicted result is positive.
Experiment¶
Beta-Rec platform provides a convenient experiment interface to use for running a series of experiments to examine models’ performances on datasets with various data split setups.

We use the Matrix Factorisation-based recommender as example and train and test it on the MovieLens-100k dataset, which adopt the leave one out data split setup. The example notebook is also provided here.
In the following content, we illustrate our experimental pipeline with the aforementioned example step by step:
Load dataset¶
First, we initiase the BaseData with an available dataset and its data split setup from the platform. You can found the availble datasets and data split functions here. An example is also given as follows:
import sys
sys.path.append("../")
from beta_rec.datasets.movielens import Movielens_100k
from beta_rec.data.base_data import BaseData
# Initialise dataset and the corresponding data split strategy
dataset = Movielens_100k()
split_dataset = dataset.load_leave_one_out(n_test=1)
data = BaseData(split_dataset)
Model Configuration¶
Next, we select an targeted models to conduct the experiments. In particular, each model has its default and corresponding configuration file, which is listed in the configs folder. There are two options to update the configuration of the selected models:
(1) Update the configuration file (e.g. mf_default.json).
(2) Update the default values of instance variables of the Experiment class (e.g. eval_scopes).
The model configuration of two MF models can be written as follows:
from beta_rec.recommenders import MatrixFactorization
from beta_rec.experiment.experiment import Experiment
# Initialise recommenders with their default configuration files
config1 = {
"config_file":"configs/mf_default.json"
}
config2 = {
"config_file":"configs/mf_default.json"
}
mf_1 = MatrixFactorization(config1)
mf_2 = MatrixFactorization(config2)
Run Experiment¶
After initialising the selected dataset and the models, we can pass these two objects to the experiment class and run experiments as follows:
# Run experiments of the recommenders on the selected dataset
Experiment(
datasets=[data],
models=[mf_1, mf_2],
).run()
beta_rec.core package¶
beta_rec.core.eval_engine module¶
This is the core implementation of the evaluation.
-
class
beta_rec.core.eval_engine.EvalEngine(config)[source]¶ Bases:
objectThe base evaluation engine.
-
predict(data_df, model, batch_eval=False)[source]¶ Make prediction for a trained model.
Parameters: - data_df (DataFrame) – A dataset to be evaluated.
- model – A trained model.
- batch_eval (Boolean) – A signal to indicate if the model is evaluated in batches.
Returns: predicted scores.
Return type: array
-
record_performance(valid_result, test_result, epoch_id)[source]¶ Record perforance result on tensorboard.
Parameters: - valid_result (dict) – Performance result of validation set.
- test_result (dict) – Performance result of testing set.
- epoch_id (int) – epoch_id.
-
seq_predict(train_seq, data_df, model, maxlen)[source]¶ Make prediction for a trained model.
Parameters: - data_df (DataFrame) – A dataset to be evaluated.
- model – A trained model.
- batch_eval (Boolean) – A signal to indicate if the model is evaluated in batches.
Returns: predicted scores.
Return type: array
-
seq_predict_time(train_seq, data_df, model, maxlen, time_span)[source]¶ Make prediction for a trained model.
Parameters: - data_df (DataFrame) – A dataset to be evaluated.
- model – A trained model.
- batch_eval (Boolean) – A signal to indicate if the model is evaluated in batches.
Returns: predicted scores.
Return type: array
-
seq_train_eval(train_seq, valid_data_df, test_data_df, model, maxlen, epoch_id=0)[source]¶ Evaluate the performance for a (validation) dataset with multiThread.
Parameters: - valid_data_df (DataFrame) – A validation dataset.
- test_data_df (DataFrame) – A testing dataset.
- model – trained model.
- epoch_id – epoch_id.
- k (int or list) – top k result to be evaluate.
-
seq_train_eval_time(train_seq, valid_data_df, test_data_df, model, maxlen, time_span, epoch_id=0)[source]¶ Evaluate the performance for a (validation) dataset with multiThread.
Parameters: - valid_data_df (DataFrame) – A validation dataset.
- test_data_df (DataFrame) – A testing dataset.
- model – trained model.
- epoch_id – epoch_id.
- k (int or list) – top k result to be evaluate.
-
test_eval(test_df_list, model)[source]¶ Evaluate the performance for a (testing) dataset list with multiThread.
Parameters: - test_df_list (list) – (testing) dataset list.
- model – trained model.
-
test_seq_predict(train_seq, valid_data_df, test_data_df, model, maxlen)[source]¶ Make prediction for a trained model.
Parameters: - data_df (DataFrame) – A dataset to be evaluated.
- model – A trained model.
- batch_eval (Boolean) – A signal to indicate if the model is evaluated in batches.
Returns: predicted scores.
Return type: array
-
test_seq_predict_time(train_seq, valid_data_df, test_data_df, model, maxlen, time_span)[source]¶ Make prediction for a trained model.
Parameters: - data_df (DataFrame) – A dataset to be evaluated.
- model – A trained model.
- batch_eval (Boolean) – A signal to indicate if the model is evaluated in batches.
Returns: predicted scores.
Return type: array
-
train_eval(valid_data_df, test_data_df, model, epoch_id=0)[source]¶ Evaluate the performance for a (validation) dataset with multiThread.
Parameters: - valid_data_df (DataFrame) – A validation dataset.
- test_data_df (DataFrame) – A testing dataset.
- model – trained model.
- epoch_id – epoch_id.
- k (int or list) – top k result to be evaluate.
-
-
class
beta_rec.core.eval_engine.SeqEvalEngine(config)[source]¶ Bases:
objectThe base evaluation engine for sequential recommendation.
-
evaluate_sequence(recommender, seq, evaluation_functions, user, given_k, look_ahead, top_n)[source]¶ Compute metrics for each sequence.
Parameters: - recommender (object) – which recommender to use
- seq (List) – the user_profile/ context
- given_k (int) – last element used as ground truth. NB if <0 it is interpreted as first elements to keep
- evaluation_functions (dict) – which function to use to evaluate the rec performance
- look_ahead (int) – number of elements in ground truth to consider. If look_ahead = ‘all’ then all the ground_truth sequence is considered
Returns: performance of recommender.
Return type: np.array(tmp_results) (1d array)
-
get_test_sequences(test_data, given_k)[source]¶ Run evaluation only over sequences longer than abs(LAST_K).
Parameters: - test_data (pandas.DataFrame) – Test set.
- given_k (int) – last element used as ground truth.
Returns: list of sequences for testing.
Return type: test_sequences (List)
-
sequence_sequential_evaluation(recommender, seq, evaluation_functions, user, given_k, look_ahead, top_n, step)[source]¶ Compute metrics for each sequence incrementally.
Parameters: - recommender (object) – which recommender to use
- seq (List) – the user_profile/ context
- given_k (int) – last element used as ground truth. NB if <0 it is interpreted as first elements to keep
- evaluation_functions (dict) – which function to use to evaluate the rec performance
- look_ahead (int) – number of elements in ground truth to consider. If look_ahead = ‘all’ then all the ground_truth sequence is considered
Returns: performance of recommender.
Return type: eval_res/eval_cnt (1d array)
-
sequential_evaluation(recommender, test_sequences, evaluation_functions, users=None, given_k=1, look_ahead=1, top_n=10, scroll=True, step=1)[source]¶ Run sequential evaluation of a recommender over a set of test sequences.
Parameters: - recommender (object) – the instance of the recommender to test.
- test_sequences (List) – the set of test sequences
- evaluation_functions (dict) – list of evaluation metric functions.
- users (List) – (optional) the list of user ids associated to each test sequence.
- given_k (int) – (optional) the initial size of each user profile, starting from the first interaction in the sequence. If <0, start counting from the end of the sequence. It must be != 0.
- look_ahead (int) – (optional) number of subsequent interactions in the sequence to be considered as ground truth. It can be any positive number or ‘all’ to extend the ground truth until the end of the sequence.
- top_n (int) – (optional) size of the recommendation list
- scroll (boolean) – (optional) whether to scroll the ground truth until the end of the sequence. If True, expand the user profile and move the ground truth forward of step interactions. Recompute and evaluate recommendations every time. If False, evaluate recommendations once per sequence without expanding the user profile.
- step (int) – (optional) number of interactions that will be added to the user profile at each step of the sequential evaluation.
Returns: the list of the average values for each evaluation metric.
Return type: metrics/len(test_sequences) (1d array)
-
test_eval_seq(test_data, recommender)[source]¶ Compute performance of the sequential models with test dataset.
Parameters: - test_data (pandas.DataFrame) – test dataset.
- recommender (Object) – Sequential recommender.
- k (int) – size of the recommendation list
Returns: None
-
train_eval_seq(valid_data, test_data, recommender, epoch_id=0)[source]¶ Compute performance of the sequential models with validation and test datasets for each epoch during training.
Parameters: - valid_data (pandas.DataFrame) – validation dataset.
- test_data (pandas.DataFrame) – test dataset.
- recommender (Object) – Sequential recommender.
- epoch_id (int) – id of the epoch.
- k (int) – size of the recommendation list
Returns: None
-
-
beta_rec.core.eval_engine.computeRePos(time_seq, time_span)[source]¶ Compute position matrix for a user.
Parameters: - time_seq ([type]) – [description]
- time_span ([type]) – [description]
Returns: [description]
Return type: [type]
-
beta_rec.core.eval_engine.evaluate(data_df, predictions, metrics, k_li)[source]¶ Evaluate the performance of a prediction by different metrics.
Parameters: - data_df (DataFrame) – the dataset to be evaluated.
- predictions (narray) – 1-D array. The predicted scores for each user-item pair in the dataset.
- metrics (list) – metrics to be evaluated.
- k_li (int or list) – top k (s) to be evaluated.
Returns: Performance result.
Return type: result_dic (dict)
-
beta_rec.core.eval_engine.test_eval_worker(testEngine, eval_data_df, prediction)[source]¶ Start a worker for the evaluation during training.
Prediction and evaluation on the testing set.
-
beta_rec.core.eval_engine.train_eval_worker(testEngine, valid_df, test_df, valid_pred, test_pred, epoch)[source]¶ Start a worker for the evaluation during training.
Parameters: - testEngine –
- valid_df –
- test_df –
- valid_pred –
- test_pred –
- epoch (int) –
Returns: dictionary with performances on validation and testing sets.
Return type: (dict,dict)
beta_rec.core.train_engine module¶
Module contents¶
Core Module.
beta_rec.data package¶
beta_rec.data.auxiliary_data module¶
beta_rec.data.base_data module¶
-
class
beta_rec.data.base_data.BaseData(split_dataset, intersect=True, binarize=True, bin_thld=0.0, normalize=False)[source]¶ Bases:
objectA plain DataBase object modeling general recommendation data. Re_index all the users and items from raw dataset.
Parameters: - split_dataset (train,valid,test) – the split dataset, a tuple consisting of training (DataFrame), validate/list of validate (DataFrame), testing/list of testing (DataFrame).
- intersect (bool, optional) – remove users and items of test/valid sets that do not exist in the train set. If the
model is able to predict for new users and new items, this can be
False. (default:True). - binarize (bool, optional) – binarize the rating column of train set 0 or 1, i.e. implicit feedback.
(default:
True). - bin_thld (int, optional) – the threshold of binarization (default:
0) normalize (bool, optional): normalize the rating column of train. set into [0, 1], i.e. explicit feedback. (default:False).
-
get_adj_mat(config)[source]¶ Get the adjacent matrix, if not previously stored then call the function to create.
This method is for NGCF model.
Returns: Different types of adjacment matrix.
-
get_constraint_mat(config)[source]¶ Get the adjacent matrix, if not previously stored then call the function to create.
This method is for NGCF model.
Returns: Different types of adjacment matrix.
-
instance_bce_loader(batch_size, device, num_negative)[source]¶ Instance a train DataLoader that have rating.
-
instance_bpr_loader(batch_size, device)[source]¶ Instance a pairwise Data_loader for training.
Sample ONE negative items for each user-item pare, and shuffle them with positive items. A batch of data in this DataLoader is suitable for a binary cross-entropy loss. # todo implement the item popularity-biased sampling
beta_rec.data.data_loaders module¶
beta_rec.data.deprecated_data module¶
beta_rec.data.deprecated_data_base module¶
-
class
beta_rec.data.deprecated_data_base.DataLoaderBase(ratings)[source]¶ Bases:
objectConstruct dataset for NCF.
-
evaluate_data¶ Create evaluation data.
-
get_adj_mat(config)[source]¶ Get the adjacent matrix, if not previously stored then call the function to create.
This method is for NGCF model.
Returns: Different types of adjacment matrix.
-
get_graph_embeddings(config)[source]¶ Get the graph embedding, if not previously stored then call the function to create.
This method is for LCFN model.
Returns: eigsh of the graph matrix
-
instance_a_train_loader(num_negatives, batch_size)[source]¶ Instance train loader for one training epoch.
-
pairwise_negative_train_loader(batch_size, device)[source]¶ Instance a pairwise Data_loader for training.
Sample ONE negative items for each user-item pare, and shuffle them with positive items. A batch of data in this DataLoader is suitable for a binary cross-entropy loss. # todo implement the item popularity-biased sampling
-
uniform_negative_train_loader(num_negatives, batch_size, device)[source]¶ Instance a Data_loader for training.
Sample ‘num_negatives’ negative items for each user, and shuffle them with positive items. A batch of data in this DataLoader is suitable for a binary cross-entropy loss. # todo implement the item popularity-biased sampling
-
-
class
beta_rec.data.deprecated_data_base.PairwiseNegativeDataset(user_tensor, pos_item_tensor, neg_item_tensor)[source]¶ Bases:
torch.utils.data.dataset.DatasetWrapper, convert <user, pos_item, neg_item> Tensor into Pytorch Dataset.
beta_rec.data.grocery_data module¶
Module contents¶
Data Module.
-
class
beta_rec.data.BaseData(split_dataset, intersect=True, binarize=True, bin_thld=0.0, normalize=False)[source]¶ Bases:
objectA plain DataBase object modeling general recommendation data. Re_index all the users and items from raw dataset.
Parameters: - split_dataset (train,valid,test) – the split dataset, a tuple consisting of training (DataFrame), validate/list of validate (DataFrame), testing/list of testing (DataFrame).
- intersect (bool, optional) – remove users and items of test/valid sets that do not exist in the train set. If the
model is able to predict for new users and new items, this can be
False. (default:True). - binarize (bool, optional) – binarize the rating column of train set 0 or 1, i.e. implicit feedback.
(default:
True). - bin_thld (int, optional) – the threshold of binarization (default:
0) normalize (bool, optional): normalize the rating column of train. set into [0, 1], i.e. explicit feedback. (default:False).
-
get_adj_mat(config)[source]¶ Get the adjacent matrix, if not previously stored then call the function to create.
This method is for NGCF model.
Returns: Different types of adjacment matrix.
-
get_constraint_mat(config)[source]¶ Get the adjacent matrix, if not previously stored then call the function to create.
This method is for NGCF model.
Returns: Different types of adjacment matrix.
-
instance_bce_loader(batch_size, device, num_negative)[source]¶ Instance a train DataLoader that have rating.
-
instance_bpr_loader(batch_size, device)[source]¶ Instance a pairwise Data_loader for training.
Sample ONE negative items for each user-item pare, and shuffle them with positive items. A batch of data in this DataLoader is suitable for a binary cross-entropy loss. # todo implement the item popularity-biased sampling
beta_rec.datasets package¶
beta_rec.datasets.ali_mobile module¶
-
class
beta_rec.datasets.ali_mobile.AliMobile(min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseAliMobile Dataset.
AliMobile dataset. This dataset is used to develop an individualized recommendation system of all items, it is similar to the taobao dataset.
The dataset can not be download by the url, you need to down the dataset by ‘https://tianchi.aliyun.com/dataset/dataDetail?dataId=46’ and then put it into the directory ali_mobile/raw
-
preprocess()[source]¶ Preprocess the raw file.
Preprocess the file downloaded via the url, convert it to a dataframe consist of the user-item interaction and save in the processed directory
Download datasets if not existed. ali_mobile_name: UserBehavior.csv
- Download ali_mobile dataset if this dataset is not existed.
- Load AliMobile <ali-mobile-interaction> table from ‘tianchi_mobile_recommend_train_user.csv’.
- Save dataset model.
-
-
beta_rec.datasets.ali_mobile.process_time(standard_time=None)[source]¶ Transform time format “xxxx-xx-xxTxx-xx-xxZ” into format “xxxx-xx-xx xx-xx-xx”.
Transform a standard time into our specified format.
Parameters: standard_time – str with format “xxxx-xx-xxTxx-xx-xxZ”. Returns: timestamp data. Return type: timestamp
beta_rec.datasets.citeulike module¶
-
class
beta_rec.datasets.citeulike.CiteULikeA(min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseCiteULike-A.
CiteULike-A dataset. The dataset can not be download by the url, you need to down the dataset by ‘https://github.com/js05212/citeulike-a’, then put it into the directory citeulike-a/raw
-
class
beta_rec.datasets.citeulike.CiteULikeT(dataset_name='citeulike-t', min_u_c=0, min_i_c=3)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseCiteULike-T.
CiteULike-T dataset. The dataset can not be download by the url, you need to down the dataset by ‘https://github.com/js05212/citeulike-t’, and then put it into the directory citeulike-t/raw/citeulike-t.
beta_rec.datasets.data_load module¶
beta_rec.datasets.data_split module¶
-
beta_rec.datasets.data_split.check_data_available(data)[source]¶ Check if a dataset is available after filtering.
Check whether a given dataset is available for later use.
Parameters: data (DataFrame) – interaction DataFrame to be processed. Raises: RuntimeError– An error occurred it there is no interaction.
-
beta_rec.datasets.data_split.feed_neg_sample(data, negative_num, item_sampler)[source]¶ Sample negative items for a interaction DataFrame.
Parameters: - data (DataFrame) – interaction DataFrame to be processed.
- negative_num (int) – number of negative items. if negative_num<0, will keep all the negative items for each user.
- item_sampler (AliasTable) – a AliasTable sampler that contains the items.
Returns: interaction DataFrame with a new ‘flag’ column labeling with “train”, “test” or “valid”.
Return type: DataFrame
-
beta_rec.datasets.data_split.filter_by_count(df, group_col, filter_col, num)[source]¶ Filter out the group_col column values that have a less than num count of filter_col.
Parameters: - df (DataFrame) – interaction DataFrame to be processed.
- group_col (string) – column name to be filtered.
- filter_col (string) – column with the filter condition.
- num (int) – minimum count condition that should be filter out.
Returns: The filtered interactions.
Return type: DataFrame
-
beta_rec.datasets.data_split.filter_user_item(df, min_u_c=5, min_i_c=5)[source]¶ Filter data by the minimum purchase number of items and users.
Parameters: - df (DataFrame) – interaction DataFrame to be processed.
- min_u_c (int) – filter the items that were purchased by less than min_u_c users.
(default:
5) - min_i_c (int) – filter the users that have purchased by less than min_i_c items.
(default:
5)
Returns: The filtered interactions
Return type: DataFrame
-
beta_rec.datasets.data_split.filter_user_item_order(df, min_u_c=5, min_i_c=5, min_o_c=5)[source]¶ Filter data by the minimum purchase number of items and users.
Parameters: - df (DataFrame) – interaction DataFrame to be processed.
- min_u_c – filter the items that were purchased by less than min_u_c users.
- (default –
5) - min_i_c – filter the users that have purchased by less than min_i_c items.
- (default –
5) - min_o_c – filter the users that have purchased by less than min_o_c orders.
- (default –
5)
Returns: The filtered DataFrame.
-
beta_rec.datasets.data_split.generate_parameterized_path(test_rate=0, random=False, n_negative=100, by_user=False)[source]¶ Generate parameterized path.
Encode parameters into path to differentiate different split parameters.
Parameters: - by_user (bool) – split by user.
- test_rate (float) – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- random (bool) – Whether random leave one item/basket as testing. only for leave_one_out and leave_one_basket.
- n_negative (int) – Number of negative samples for testing and validation data.
Returns: A string that encodes parameters.
Return type: string
-
beta_rec.datasets.data_split.generate_random_data(n_interaction, user_id, item_id)[source]¶ Generate random data for testing.
Generate random data for unit test.
-
beta_rec.datasets.data_split.leave_one_basket(data, random=False)[source]¶ leave_one_basket split.
Parameters: - data (DataFrame) – interaction DataFrame to be split.
- random (bool) – Whether randomly leave one item/basket as testing. only for leave_one_out and leave_one_basket.
Returns: DataFrame that have already by labeled by a col with “train”, “test” or “valid”.
Return type: DataFrame
-
beta_rec.datasets.data_split.leave_one_out(data, random=False)[source]¶ leave_one_out split.
Parameters: - data (DataFrame) – interaction DataFrame to be split.
- random (bool) – Whether randomly leave one item/basket as testing. only for leave_one_out and leave_one_basket.
Returns: DataFrame that have already by labeled by a col with “train”, “test” or “valid”.
Return type: DataFrame
-
beta_rec.datasets.data_split.load_split_data(path, n_test=10)[source]¶ Load split DataFrame from a specified path.
Parameters: - path (string) – split data path.
- n_test – number of testing and validation datasets. If n_test==0, will load the original (no negative items) valid and test datasets.
Returns: DataFrame of training interaction, DataFrame list of validation interaction, DataFrame list of testing interaction,
Return type: (DataFrame, list(DataFrame), list(DataFrame))
-
beta_rec.datasets.data_split.random_basket_split(data, test_rate=0.1, by_user=False)[source]¶ random_basket_split.
Parameters: - data (DataFrame) – interaction DataFrame to be split.
- test_rate (float) – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- by_user (bool) – Default False. - True: user-based split, - False: global split,
Returns: DataFrame that have already by labeled by a col with “train”, “test” or “valid”.
Return type: DataFrame
-
beta_rec.datasets.data_split.random_split(data, test_rate=0.1, by_user=False)[source]¶ random_basket_split.
Parameters: - data (DataFrame) – interaction DataFrame to be split.
- test_rate (float) – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- by_user (bool) – Default False. - Ture: user-based split, - False: global split,
Returns: DataFrame that have already by labeled by a col with “train”, “test” or “valid”.
Return type: DataFrame
-
beta_rec.datasets.data_split.save_split_data(data, base_dir, data_split='leave_one_basket', parameterized_dir=None, suffix='train.npz')[source]¶ Save DataFrame to compressed npz.
Parameters: - data (DataFrame) – interaction DataFrame to be saved.
- parameterized_dir (string) – data_split parameter string.
- suffix (string) – suffix of the data to be saved.
- base_dir (string) – directory to save.
- data_split (string) – sub folder name for saving the data.
-
beta_rec.datasets.data_split.split_data(data, split_type, test_rate, random=False, n_negative=100, save_dir=None, by_user=False, n_test=10)[source]¶ Split data by split_type and other parameters.
Parameters: - data (DataFrame) – interaction DataFrame to be split
- split_type (string) – options can be: - random - random_basket - leave_one_out - leave_one_basket - temporal - temporal_basket
- random (bool) – Whether random leave one item/basket as testing. only for leave_one_out and leave_one_basket.
- test_rate (float) – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- n_negative (int) – Number of negative samples for testing and validation data.
- save_dir (string or Path) – Default None. If specified, the split data will be saved to the dir.
- by_user (bool) – Default False. - True: user-based split, - False: global split,
- n_test (int) – Default 10. The number of testing and validation copies.
Returns: The split data. Note that the returned data will not have negative samples.
Return type: DataFrame
-
beta_rec.datasets.data_split.temporal_basket_split(data, test_rate=0.1, by_user=False)[source]¶ temporal_basket_split.
Parameters: - data (DataFrame) – interaction DataFrame to be split. It must have a col DEFAULT_ORDER_COL.
- test_rate (float) – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- by_user (bool) – Default False. - True: user-based split, - False: global split,
Returns: DataFrame that have already by labeled by a col with “train”, “test” or “valid”.
Return type: DataFrame
-
beta_rec.datasets.data_split.temporal_split(data, test_rate=0.1, by_user=False)[source]¶ temporal_split.
Parameters: - data (DataFrame) – interaction DataFrame to be split.
- test_rate (float) – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- by_user (bool) – bool. Default False. - True: user-based split, - False: global split,
Returns: DataFrame that have already by labeled by a col with “train”, “test” or “valid”.
Return type: DataFrame
beta_rec.datasets.dataset_base module¶
-
class
beta_rec.datasets.dataset_base.DatasetBase(dataset_name, min_u_c=0, min_i_c=3, min_o_c=0, url=None, root_dir=None, manual_download_url=None, processed_leave_one_out_url='', processed_leave_one_basket_url='', processed_random_split_url='', processed_random_basket_split_url='', processed_temporal_split_url='', processed_temporal_basket_split_url='', tips=None)[source]¶ Bases:
objectBase class for processing raw dataset into interactions, making and loading data splits.
This is an beta dataset which can derive to other dataset. Several directory that store the dataset file would be created in the initial process.
-
dataset_name¶ the dataset name.
-
min_u_c¶ filter the items that were purchased by less than min_u_c users.
(default:
0) min_i_c: filter the users that have purchased by less than min_i_c items. (default:3) min_o_c: filter the users that have purchased by less than min_o_c orders. (default:0)url: the url of raw files. manual_download_url: the url that users use to download raw files manually
-
download()[source]¶ Download the raw dataset.
Download the dataset with the given url and unpack the file.
-
load_interaction()[source]¶ Load the user-item interaction. And filter users, items or orders.
Returns: Loaded interactions after filtering Return type: DataFrame Load the interaction from the processed file(Need to preprocess the raw file before loading)
-
load_leave_one_basket(random=False, n_negative=100, n_test=10, download=False, force_redo=False)[source]¶ Load split date generated by leave_one_basket without random select.
Load split data generated by leave_one_basket without random select from Onedrive.
Parameters: - random – bool. Whether randomly leave one basket as testing.
- n_negative – Number of negative samples for testing and validation data.
- download (bool) – Whether download the split produced by the Beta-rec team (With random seed:2020).
- force_redo (bool) – Whether force to re-split the dataset.
- n_test – int. Default 10. The number of testing and validation copies. If n_test==0, will load the original (no negative items) valid and test datasets.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
load_leave_one_out(random=False, n_negative=100, n_test=10, download=False, force_redo=False)[source]¶ Load split data generated by leave_out_out without random select.
Load split data generated by leave_out_out without random select from Onedrive.
Parameters: - random (bool) – . Whether randomly leave one item as testing.
- n_negative (int) – Number of negative samples for testing and validation data.
- download (bool) – Whether download the split produced by the Beta-rec team (With random seed:2020).
- force_redo (bool) – Whether force to re-split the dataset.
- n_test (int) – Default 10. The number of testing and validation copies. If n_test==0, will load the original (no negative items) valid and test datasets.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
load_random_basket_split(test_rate=0.1, random=False, n_negative=100, by_user=False, n_test=10, download=False, force_redo=False)[source]¶ Load split date generated by random_basket_split.
Load split data generated by random_basket_split from Onedrive, with test_rate = 0.1 and by_user = False.
Parameters: - test_rate – percentage of the test data. Note that percentage of the validation data will be the same as test data.
- random – bool. Whether randomly leave one basket as testing.
- download (bool) – Whether download the split produced by the Beta-rec team (With random seed:2020).
- force_redo (bool) – Whether force to re-split the dataset.
- n_negative – Number of negative samples for testing and validation data.
- by_user – bool. Default False. - True: user-based split, - False: global split,
- n_test – int. Default 10. The number of testing and validation copies. If n_test==0, will load the original (no negative items) valid and test datasets.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
load_random_split(test_rate=0.1, random=False, n_negative=100, by_user=False, n_test=10, download=False, force_redo=False)[source]¶ Load split date generated by random_split.
Load split data generated by random_split from Onedrive, with test_rate = 0.1 and by_user = False.
Parameters: - test_rate – percentage of the test data. Note that percentage of the validation data will be the same as test data.
- random – bool. Whether randomly leave one basket as testing.
- download (bool) – Whether download the split produced by the Beta-rec team (With random seed:2020).
- force_redo (bool) – Whether force to re-split the dataset.
- n_negative – Number of negative samples for testing and validation data.
- by_user – bool. Default False. - Ture: user-based split, - False: global split,
- n_test – int. Default 10. The number of testing and validation copies. If n_test==0, will load the original (no negative items) valid and test datasets.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
load_split(config)[source]¶ Load split data by config dict.
Parameters: config (dict) – config (dict): Dictionary of configuration Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing Return type: train_data (DataFrame)
-
load_temporal_basket_split(test_rate=0.1, n_negative=100, by_user=False, n_test=10, download=False, force_redo=False)[source]¶ Load split date generated by temporal_basket_split.
Load split data generated by temporal_basket_split from Onedrive, with test_rate = 0.1 and by_user = False.
Parameters: - test_rate – percentage of the test data. Note that percentage of the validation data will be the same as test data.
- n_negative – Number of negative samples for testing and validation data.
- by_user – bool. Default False. - True: user-based split, - False: global split,
- n_test – int. Default 10. The number of testing and validation copies. If n_test==0, will load the original (no negative items) valid and test datasets.
- download (bool) – Whether download the split produced by the Beta-rec team (With random seed:2020).
- force_redo (bool) – Whether force to re-split the dataset.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
load_temporal_split(test_rate=0.1, n_negative=100, by_user=False, n_test=10, download=False, force_redo=False)[source]¶ Load split date generated by temporal_split.
Load split data generated by temporal_split from Onedrive, with test_rate = 0.1 and by_user = False.
Parameters: - test_rate – percentage of the test data. Note that percentage of the validation data will be the same as test data.
- n_negative – Number of negative samples for testing and validation data.
- by_user – bool. Default False. - True: user-based split, - False: global split,
- n_test – int. Default 10. The number of testing and validation copies. If n_test==0, will load the original (no negative items) valid and test datasets.
- download (bool) – Whether download the split produced by the Beta-rec team (With random seed:2020).
- force_redo (bool) – Whether force to re-split the dataset.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
make_leave_one_basket(data=None, random=False, n_negative=100, n_test=10)[source]¶ Generate split data with leave_one_basket.
Generate split data with leave_one_basket method.
Parameters: - data (DataFrame) – DataFrame to be split.
- random – bool. Whether randomly leave one basket as testing.
- n_negative – Number of negative samples for testing and validation data.
- n_test – int. Default 10. The number of testing and validation copies.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
make_leave_one_out(data=None, random=False, n_negative=100, n_test=10)[source]¶ Generate split data with leave_one_out.
Generate split data with leave_one_out method.
Parameters: - data (DataFrame) –
DataFrame to be split. - Default is None. It will load the raw interaction, with a default filter
’’’ filter_user_item(data, min_u_c=0, min_i_c=3) ‘’’- Users can specify their filtered data by using filter methods in data_split.py
- random – bool. Whether randomly leave one item as testing.
- n_negative – Number of negative samples for testing and validation data.
- n_test – int. Default 10. The number of testing and validation copies.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
- data (DataFrame) –
-
make_random_basket_split(data=None, test_rate=0.1, n_negative=100, by_user=False, n_test=10)[source]¶ Generate split data with random_basket_split.
Generate split data with random_basket_split method.
Parameters: - data (DataFrame) – DataFrame to be split.
- test_rate – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- n_negative – Number of negative samples for testing and validation data.
- by_user – bool. Default False. - True: user-based split, - False: global split,
- n_test – int. Default 10. The number of testing and validation copies.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
make_random_split(data=None, test_rate=0.1, n_negative=100, by_user=False, n_test=10)[source]¶ Generate split data with random_split.
Generate split data with random_split method
Parameters: - data (DataFrame) – DataFrame to be split.
- Default is None. It will load the raw interaction, with a default filter
` data = filter_user_item(data, min_u_c=3, min_i_c=3) `- Users can specify their filtered data by using filter methods in data_split.py - test_rate – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- n_negative – Number of negative samples for testing and validation data.
- by_user – bool. Default False. - True: user-based split, - False: global split,
- n_test – int. Default 10. The number of testing and validation copies.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
- data (DataFrame) – DataFrame to be split.
- Default is None. It will load the raw interaction, with a default filter
-
make_temporal_basket_split(data=None, test_rate=0.1, n_negative=100, by_user=False, n_test=10)[source]¶ Generate split data with temporal_basket_split.
Generate split data with temporal_basket_split method.
Parameters: - data (DataFrame) – DataFrame to be split. - Default is None. It will load the raw interaction, with a default filter - Users can specify their filtered data by using filter methods in data_split.py
- test_rate – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- n_negative – Number of negative samples for testing and validation data.
- by_user – bool. Default False. - True: user-based split, - False: global split,
- n_test – int. Default 10. The number of testing and validation copies.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
-
make_temporal_split(data=None, test_rate=0.1, n_negative=100, by_user=False, n_test=10)[source]¶ Generate split data with temporal_split.
Generate split data with temporal_split method.
Parameters: - data (DataFrame) – DataFrame to be split.
- Default is None. It will load the raw interaction, with a default filter
` data = filter_user_item(data, min_u_c=3, min_i_c=3) `- Users can specify their filtered data by using filter methods in data_split.py - test_rate – percentage of the test data. Note that percentage of the validation data will be the same as testing.
- n_negative – Number of negative samples for testing and validation data.
- by_user – bool. Default False. - True: user-based split, - False: global split,
- n_test – int. Default 10. The number of testing and validation copies.
Returns: Interaction for training. valid_data list(DataFrame): List of interactions for validation test_data list(DataFrame): List of interactions for testing
Return type: train_data (DataFrame)
- data (DataFrame) – DataFrame to be split.
- Default is None. It will load the raw interaction, with a default filter
-
beta_rec.datasets.diginetica module¶
-
class
beta_rec.datasets.diginetica.Diginetica(dataset_name='diginetica', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseDiginetica Dataset.
This is a dataset provided by DIGINETICA and its partners containing anonymized search and browsing logs, product data, anonymized transactions, and a large data set of product images. The participants have to predict search relevance of products according to the personal shopping, search, and browsing preferences of the users. Both ‘query-less’ and ‘query-full’ sessions are possible. The evaluation is based on click and transaction data.
The dataset can not be download by the url, you need to down the dataset by ‘https://cikm2016.cs.iupui.edu/cikm-cup/’ then put it into the directory diginetica/raw, then unzip this file and rename the new directory to ‘diginetica’.
Note: you also need unzip files in ‘diginetica/raw/diginetica’.
-
preprocess()[source]¶ Preprocess the raw file.
Preprocess the file downloaded via the url, convert it to a dataframe consist of the user-item interaction and save in the processed directory
Download datasets if not existed. diginetica_name: train-item-views.csv
- Download diginetica dataset if this dataset is not existed.
- Load diginetica <diginetica-item-views> table from ‘diginetica.csv’.
- Add rating column and create timestamp column.
- Save data model.
-
-
beta_rec.datasets.diginetica.process_time(standard_time=None)[source]¶ Transform time format “xxxx-xx-xx” into format “xxxx-xx-xx xx-xx-xx”.
If there is no specified hour-minute-second data, we use 00:00:00 as default value.
Parameters: standard_time – str with format “xxxx-xx-xx”. Returns: timestamp data. Return type: timestamp
beta_rec.datasets.dunnhumby module¶
-
class
beta_rec.datasets.dunnhumby.Dunnhumby(min_u_c=0, min_i_c=3, min_o_c=0, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseDunnhumby Dataset.
If the dataset can not be download by the url, you need to down the dataset by the link:
then put it into the directory dunnhumby/raw
beta_rec.datasets.epinions module¶
-
class
beta_rec.datasets.epinions.Epinions(dataset_name='epinions', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseEpinions Dataset.
beta_rec.datasets.gowalla module¶
-
class
beta_rec.datasets.gowalla.Gowalla(dataset_name='gowalla', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseGowalla Dataset.
Gowalla is a location-based social networking website where users share their locations by checking-in. The friendship network is undirected and was collected using their public API, and consists of 196,591 nodes and 950,327 edges. We have collected a total of 6,442,890 check-ins of these users over the period of Feb. 2009 - Oct. 2010.
If the dataset can not be download by the url, you need to down the dataset by the link:
then put it into the directory gowalla/raw and unzip it.
-
preprocess()[source]¶ Preprocess the raw file.
Preprocess the file downloaded via the url, convert it to a dataframe consist of the user-item interaction and save in the processed directory
Download datasets if not existed. Gowalla_checkin_name: Gowalla_totalCheckins.txt Gowalla_edges_name : Gowalla_edges.txt
- Download gowalla dataset if this dataset is not existed.
- Load gowalla <Gowalla_checkin> table from ‘Gowalla_totalCheckins.txt’.
- Process time columns and transform it into timestamp.
- Rename and save dataset model.
-
beta_rec.datasets.hetrec module¶
-
class
beta_rec.datasets.hetrec.Delicious_2k(dataset_name='delicious-2k', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBasedelicious-2k Dataset.
This dataset contains social networking, bookmarking, and tagging information from a set of 2K users from Delicious social bookmarking system. http://www.delicious.com.
If the dataset can not be download by the url, you need to down the dataset in the following link: ‘http://files.grouplens.org/datasets/hetrec2011/hetrec2011-delicious-2k.zip’ then put it into the directory delicious-2k/raw.
-
class
beta_rec.datasets.hetrec.LastFM_2k(dataset_name='lastfm-2k', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseLastfm-2k Dataset.
This dataset contains social networking, tagging, and music artist listening information from a set of 2K users from Last.fm online music system.
If the dataset can not be download by the url, you need to down the dataset by the link:
then put it into the directory delicious-2k/raw.
-
class
beta_rec.datasets.hetrec.MovieLens_2k(dataset_name='movielens-2k', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseMovieLens-2k Dataset.
If the dataset can not be download by the url, you need to down the dataset by the link: ‘http://files.grouplens.org/datasets/hetrec2011/hetrec2011-movielens-2k-v2.zip’ then put it into the directory `movielens-2k/raw.
beta_rec.datasets.instacart module¶
-
class
beta_rec.datasets.instacart.Instacart(dataset_name='instacart', min_u_c=0, min_i_c=3, min_o_c=0, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseInstacart Dataset.
If the dataset can not be download by the url, you need to down the dataset by the link:
then put it into the directory instacart/raw, unzip this file and rename the directory in ‘instacart’.
Instacart dataset is used to predict when users buy product for the next time, we construct it with structure [order_id, product_id].
-
preprocess()[source]¶ Preprocess the raw file.
Preprocess the file downloaded via the url, convert it to a dataframe consist of the user-item interaction and save in the processed directory.
Download and load datasets 1. Download instacart dataset if this dataset is not existed. 2. Load <order> table and <order_products> table from “orders.csv” and “order_products__train.csv”. 3. Merge the two tables above. 4. Add additional columns [rating, timestamp]. 5. Rename columns and save data model.
-
-
class
beta_rec.datasets.instacart.Instacart_25(dataset_name='instacart_25', min_u_c=0, min_i_c=3, min_o_c=0)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseInstacart Dataset.
If the dataset can not be download by the url, you need to down the dataset by the link:
then put it into the directory instacart/raw, unzip this file and rename the directory in ‘instacart’.
Instacart dataset is used to predict when users buy product for the next time, we construct it with structure [order_id, product_id].
-
preprocess()[source]¶ Preprocess the raw file.
Preprocess the file downloaded via the url, convert it to a dataframe consist of the user-item interaction and save in the processed directory
Download and load datasets 1. Download instacart dataset if this dataset is not existed. 2. Load <order> table and <order_products> table from “orders.csv” and “order_products__train.csv”. 3. Merge the two tables above. 4. Add additional columns [rating, timestamp]. 5. Rename columns and save data model.
-
beta_rec.datasets.last_fm module¶
-
class
beta_rec.datasets.last_fm.LastFM(dataset_name='last_fm', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseLastFM Dataset.
beta_rec.datasets.movielens module¶
-
class
beta_rec.datasets.movielens.Movielens_100k(dataset_name='ml_100k', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseMovielens 100k Dataset.
-
load_fea_vec()[source]¶ Load feature vectors for users and items.
1. For items (movies), we use the last 19 fields as feature, which are the genres, with 1 indicating the movie is of that genre, and 0 indicating it is not; movies can be in several genres at once.
2. For users, we construct one_hot encoding for age, gender and occupation as their feature, where ages are categorized into 8 groups.
Returns: The first column is the user id, rest column are feat vectors. item_feat (numpy.ndarray): The first column is the itm id, rest column are feat vectors. Return type: user_feat (numpy.ndarray)
-
make_fea_vec()[source]¶ Make feature vectors for users and items.
1. For items (movies), we use the last 19 fields as feature, which are the genres, with 1 indicating the movie is of that genre, and 0 indicating it is not; movies can be in several genres at once.
2. For users, we construct one_hot encoding for age, gender and occupation as their feature, where ages are categorized into 8 groups.
Returns: The first column is the user id, rest column are feat vectors. item_feat (numpy.ndarray): The first column is the item id, rest column are feat vectors. Return type: user_feat (numpy.ndarray)
-
-
class
beta_rec.datasets.movielens.Movielens_1m(dataset_name='ml_1m', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseMovielens 1m Dataset.
-
class
beta_rec.datasets.movielens.Movielens_25m(dataset_name='ml_25m', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseMovielens 25m Dataset.
beta_rec.datasets.retailrocket module¶
-
class
beta_rec.datasets.retailrocket.RetailRocket(dataset_name='retailrocket', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseRetailRocket Dataset.
This data has been collected from a real-world e-commerce website. It is raw data without any content transformations, however, all values are hashed due to confidential issue. The purpose of publishing is to motivate researches in the field of recommendation systems with implicit feedback.
If the dataset can not be download by the url, you need to down the dataset by the link:
then put it into the directory retailrocket/raw and unzip it.
-
preprocess()[source]¶ Preprocess the raw file.
Preprocess the file downloaded via the url, convert it to a DataFrame consist of the user-item interaction and save in the processed directory.
Download dataset if not existed. retail_rocket_name: UserBehavior.csv
- Download RetailRocket dataset if this dataset is not existed.
- Load RetailRocket <retail-rocket-interaction> table from ‘events.csv’.
- Save dataset model.
-
beta_rec.datasets.seq_data_utils module¶
-
class
beta_rec.datasets.seq_data_utils.SeqDataset(data, print_info=True)[source]¶ Bases:
torch.utils.data.dataset.DatasetSequential Dataset.
-
beta_rec.datasets.seq_data_utils.collate_fn(data)[source]¶ Pad the sequences.
This function will be used to pad the sessions to max length in the batch and transpose the batch from batch_size x max_seq_len to max_seq_len x batch_size. It will return padded vectors, labels and lengths of each session (before padding) It will be used in the Dataloader.
Parameters: data (pytorch Dataset) – Sequential dataset. Returns: Padded vectors. labels (Tensor): Target item. lens (list): Lengths of each padded vector. Return type: padded_sesss (Tensor)
-
beta_rec.datasets.seq_data_utils.create_seq_db(data)[source]¶ Convert interactions of a user to a sequence.
Parameters: data (pandas.DataFrame) – The dataset to be transformed. Returns: Transformed dataset with “col_user” and “col_sequence”. Return type: result (pandas.DataFrame)
-
beta_rec.datasets.seq_data_utils.dataset_to_seq_target_format(data)[source]¶ Convert a list of sequences to (seq,target) format.
Parameters: data (pandas.DataFrame) – The dataset to be transformed. Returns: Context sequence. labs (List): Labels of the context sequence, each element is the last item in the origin sequence. Return type: out_seqs (List)
-
beta_rec.datasets.seq_data_utils.load_dataset(config)[source]¶ Load datasets.
Parameters: config (dict) – Dictionary of configuration. Returns: Full dataset. Return type: dataset (pandas.DataFrame)
-
beta_rec.datasets.seq_data_utils.reindex_items(train_data, valid_data=None, test_data=None)[source]¶ Reindex the item ids.
Item ids are reindexed from 1. “0” is left for padding.
Parameters: - train_data (pandas.DataFrame) – Training set.
- valid_data (pandas.DataFrame) – Validation set.
- test_data (pandas.DataFrame) – Test set.
Returns: Reindexed training set. valid_data (pandas.DataFrame): Reindexed validation set. test_data (pandas.DataFrame): Reindexed test set.
Return type: train_data (pandas.DataFrame)
beta_rec.datasets.tafeng module¶
-
class
beta_rec.datasets.tafeng.Tafeng(dataset_name='tafeng', min_u_c=0, min_i_c=3, min_o_c=0, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseTafeng Dataset.
The dataset can not be download by the url, you need to down the dataset by ‘https://1drv.ms/u/s!AjMahLyQeZqugjc2k3eCAwKavccB?e=Qn5ppw’ then put it into the directory tafeng/raw.
beta_rec.datasets.taobao module¶
-
class
beta_rec.datasets.taobao.Taobao(dataset_name='taobao', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseTaobao Dataset.
This dataset is created by randomly selecting about 1 million users who have behaviors including click, purchase, adding item to shopping cart and item favoring during November 25 to December 03, 2017.
The dataset is organized in a very similar form to MovieLens-20M, i.e., each line represents a specific user-item interaction, which consists of user ID, item ID, item’s category ID, behavior type and timestamp, separated by commas.
The dataset can not be download by the url, you need to down the dataset by ‘https://tianchi.aliyun.com/dataset/dataDetail?dataId=649’ then put it into the directory taobao/raw.
-
preprocess()[source]¶ Preprocess the raw file.
Preprocess the file downloaded via the url, convert it to a dataframe consist of the user-item interaction and save in the processed directory.
Download datasets if not existed. taobao_name: UserBehavior.csv.
- Download taobao dataset if this dataset is not existed.
- Load taobao <taobao-interaction> table from ‘taobao.csv’.
- Save dataset model.
-
beta_rec.datasets.yelp module¶
-
class
beta_rec.datasets.yelp.Yelp(dataset_name='yelp', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseYelp Dataset.
The dataset can not be download by the url, you need to down the dataset by ‘https://www.yelp.com/dataset’ then put it into the directory yelp/raw/yelp.
beta_rec.datasets.yoochoose module¶
-
class
beta_rec.datasets.yoochoose.YooChoose(dataset_name='yoochoose', min_u_c=0, min_i_c=3, root_dir=None)[source]¶ Bases:
beta_rec.datasets.dataset_base.DatasetBaseYooChoose Dataset.
Task of YooChoose dataset: given a sequence of click events performed by some users during a typical session in an e-commerce website, the goal is to predict whether the user is going to buy something or not, and if he is buying, what would be the items he is going to buy. The task could therefore be divided into two sub goals:
- Is the user going to buy items in this session? YES|NO
- If yes, what are the items that are going to be bought?
- This dataset contains two subsets:
- yoochoose-clicks.dat
- SessionID: the id of the session.
- Timestamp: the time when the click occurred.
- ItemID: the unique identifier of the item.
- Category: the category of the item.
- yoochoose-buys.dat
- SessionID: the id of the session.
- Timestamp: the time when the click occurred.
- ItemID: the unique identifier of the item.
- Price: the price of the item.
- Quantity: how many of this item were bought.
If the dataset can not be download by the url, you need to down the dataset by the link:
then put it into the directory yoochoose/raw and unzip it.
-
preprocess()[source]¶ Preprocess the raw file.
Preprocess the file downloaded via the url, convert it to a dataframe consist of the user-item interaction and save in the processed directory.
Download datasets if not existed. yoochoose_name: yoochoose-buys.dat
- Download gowalla dataset if this dataset is not existed.
- Load yoochoose <yoochoose-buy> table from ‘yoochoose-buys.dat’.
- Rename and save dataset model.
Module contents¶
Datasets Module.
beta_rec.models package¶
beta_rec.models.cmn module¶
-
class
beta_rec.models.cmn.CollaborativeMemoryNetwork(config, user_embeddings, item_embeddings, item_user_list, device)[source]¶ Bases:
torch.nn.modules.module.ModuleCollaborativeMemoryNetwork Class.
-
class
beta_rec.models.cmn.cmnEngine(config, user_embeddings, item_embeddings, item_user_list)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineCMN Engine.
beta_rec.models.gmf module¶
-
class
beta_rec.models.gmf.GMFEngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineEngine for training & evaluating GMF model.
beta_rec.models.lightgcn module¶
-
class
beta_rec.models.lightgcn.LightGCN(config, norm_adj)[source]¶ Bases:
torch.nn.modules.module.ModuleModel initialisation, embedding generation and prediction of NGCF.
-
class
beta_rec.models.lightgcn.LightGCNEngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineLightGCNEngine Class.
beta_rec.models.mf module¶
-
class
beta_rec.models.mf.MF(config)[source]¶ Bases:
torch.nn.modules.module.ModuleA pytorch Module for Matrix Factorization.
-
class
beta_rec.models.mf.MFEngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineMFEngine Class.
beta_rec.models.mlp module¶
-
class
beta_rec.models.mlp.MLPEngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineEngine for training & evaluating GMF model.
beta_rec.models.narm module¶
-
class
beta_rec.models.narm.NARM(config)[source]¶ Bases:
torch.nn.modules.module.ModuleNeural Attentive Session Based Recommendation Model Class.
Parameters: - n_items (int) – the number of items.
- hidden_size (int) – the hidden size of gru.
- embedding_dim (int) – the dimension of item embedding.
- batch_size (int) –
- n_layers (int) – the number of gru layers.
Initialize hidden layers.
-
class
beta_rec.models.narm.NARMEngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineEngine for training & evaluating NARM model.
-
predict(user_profile, batch=1)[source]¶ Predict the next item given user profile.
Parameters: - user_profile (List) – Contains the item IDs of the events.
- batch (int) – Prediction batch size.
Returns: Prediction scores for selected items for every event of the batch.
Return type: preds (List)
-
beta_rec.models.ncf module¶
-
class
beta_rec.models.ncf.NeuMFEngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineEngine for training & evaluating GMF model.
beta_rec.models.ngcf module¶
-
class
beta_rec.models.ngcf.NGCF(config, norm_adj)[source]¶ Bases:
torch.nn.modules.module.ModuleModel initialisation, embedding generation and prediction of NGCF.
-
forward(norm_adj)[source]¶ Perform GNN function on users and item embeddings.
Parameters: norm_adj (torch sparse tensor) – the norm adjacent matrix of the user-item interaction matrix. Returns: processed user embeddings. i_g_embeddings (tensor): processed item embeddings. Return type: u_g_embeddings (tensor)
-
-
class
beta_rec.models.ngcf.NGCFEngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineNGCFEngine Class.
-
bpr_loss(users, pos_items, neg_items)[source]¶ Bayesian Personalised Ranking (BPR) pairwise loss function.
Note that the sizes of pos_scores and neg_scores should be equal.
Parameters: - pos_scores (tensor) – Tensor containing predictions for known positive items.
- neg_scores (tensor) – Tensor containing predictions for sampled negative items.
Returns: loss.
-
beta_rec.models.pairwise_ngcf module¶
beta_rec.models.torch_engine module¶
-
class
beta_rec.models.torch_engine.ModelEngine(config)[source]¶ Bases:
objectMeta Engine for training & evaluating NCF model.
Note: Subclass should implement self.model!
-
bce_loss(scores, ratings)[source]¶ Binary Cross-Entropy (BCE) pointwise loss, also known as log loss or logistic loss.
Parameters: - scores (tensor) – Tensor containing predictions for both positive and negative items.
- ratings (tensor) – Tensor containing ratings for both positive and negative items.
Returns: loss.
-
bpr_loss(pos_scores, neg_scores)[source]¶ Bayesian Personalised Ranking (BPR) pairwise loss function.
Note that the sizes of pos_scores and neg_scores should be equal.
Parameters: - pos_scores (tensor) – Tensor containing predictions for known positive items.
- neg_scores (tensor) – Tensor containing predictions for sampled negative items.
Returns: loss.
-
beta_rec.models.triple2vec module¶
-
class
beta_rec.models.triple2vec.Triple2vec(config)[source]¶ Bases:
torch.nn.modules.module.ModuleTriple2vec Class.
-
class
beta_rec.models.triple2vec.Triple2vecEngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineEngine for training Triple model.
beta_rec.models.vbcar module¶
-
class
beta_rec.models.vbcar.VBCAR(config)[source]¶ Bases:
torch.nn.modules.module.ModuleVBCAR Class.
-
class
beta_rec.models.vbcar.VBCAREngine(config)[source]¶ Bases:
beta_rec.models.torch_engine.ModelEngineEngine for training & evaluating GMF model.
beta_rec.models.vlml module¶
-
class
beta_rec.models.vlml.VariableLengthMemoryLayer(hops, emb_dim, device)[source]¶ Bases:
torch.nn.modules.module.ModuleVariableLengthMemoryLayer Class.
-
apply_attention_memory(memory, output_memory, query, memory_mask=None, maxlen=None)[source]¶ Apply attention memory.
:param : param memory: [batch size, max length, embedding size], typically Matrix M. :param : param output_memory: [batch size, max length, embedding size], typically Matrix C. :param : param query: [batch size, embed size], typically u. :param : param memory_mask: [batch size] dim Tensor, the length of each sequence if variable length. :param : param maxlen: int/Tensor, the maximum sequence padding length; if None it infers based on the max of
memory_mask.- :param : returns: AttentionOutput
output: [batch size, embedding size]. weight: [batch size, max length], the attention weights applied to
the output representation.
-
mask_mod(inputs, mask_length, maxlen=None)[source]¶ Use a memory mask.
Apply a memory mask such that the values we mask result in being the minimum possible value we can represent with a float32.
Parameters: - inputs – [batch size, length], dtype=tf.float32.
- memory_mask – [batch_size] shape Tensor of ints indicating the length of inputs.
- maxlen – Sets the maximum length of the sequence; if None, inferred from inputs.
Returns: [batch size, length] dim Tensor with the mask applied.
-
Module contents¶
Models Module.
beta_rec.utils package¶
beta_rec.utils.alias_table module¶
-
class
beta_rec.utils.alias_table.AliasTable(obj_freq)[source]¶ Bases:
objectAliasTable Class.
A list of indices of tokens in the vocab following a power law distribution, used to draw negative samples.
-
sample(count, obj_num=1, no_repeat=False)[source]¶ Generate samples.
Parameters: - count – the number of tokens in a draw.
- obj_num – the number of draws.
- no_repeat – whether repeat tokens are allowed in a single draw.
Returns: A list of tokens.
Raises: ValueError– count is larger than vocab_size when no_repeat is True.
-
beta_rec.utils.common_util module¶
-
class
beta_rec.utils.common_util.DictToObject(dictionary)[source]¶ Bases:
objectPython dict to object.
-
beta_rec.utils.common_util.ensureDir(dir_path)[source]¶ Ensure a dir exist, otherwise create the path.
Parameters: dir_path (str) – the target dir.
-
beta_rec.utils.common_util.get_data_frame_from_gzip_file(path)[source]¶ Get Dataframe from a gzip file.
Parameters: the file path of gzip file. (path) – Returns: A dataframe extracted from the gzip file.
-
beta_rec.utils.common_util.get_dataframe_from_npz(data_file)[source]¶ Get the DataFrame from npz file.
Get the DataFrame from npz file.
Parameters: data_file (str or Path) – File path. Returns: the unzip data. Return type: DataFrame
-
beta_rec.utils.common_util.get_random_rep(raw_num, dim)[source]¶ Generate a random embedding from a normal (Gaussian) distribution.
Parameters: - raw_num – Number of raw to be generated.
- dim – The dimension of the embeddings.
Returns: ndarray or scalar. Drawn samples from the normal distribution.
-
beta_rec.utils.common_util.normalized_adj_single(adj)[source]¶ Missing docs.
Parameters: adj – Returns: None.
-
beta_rec.utils.common_util.parse_gzip_file(path)[source]¶ Parse gzip file.
Parameters: path – the file path of gzip file.
-
beta_rec.utils.common_util.print_dict_as_table(dic, tag=None, columns=['keys', 'values'])[source]¶ Print a dictionary as table.
Parameters: - dic (dict) – dict object to be formatted.
- tag (str) – A name for this dictionary.
- columns ([str,str]) – default [“keys”, “values”]. columns name for keys and values.
Returns: None
-
beta_rec.utils.common_util.save_dataframe_as_npz(data, data_file)[source]¶ Save DataFrame in compressed format.
Save and convert the DataFrame to npz file. :param data: DataFrame to be saved. :type data: DataFrame :param data_file: Target file path.
-
beta_rec.utils.common_util.save_to_csv(result, result_file)[source]¶ Save a result dict to disk.
Parameters: - result – The result dict to be saved.
- result_file – The file path to be saved.
-
beta_rec.utils.common_util.set_seed(seed)[source]¶ Initialize all the seed in the system.
Parameters: seed – A global random seed.
-
beta_rec.utils.common_util.timeit(method)[source]¶ Generate decorator for tracking the execution time for the specific method.
Parameters: method – The method need to timeit. - To use:
@timeit def method(self):
pass
Returns: None
-
beta_rec.utils.common_util.un_zip(file_name, target_dir=None)[source]¶ Unzip zip files.
Parameters: - file_name (str or Path) – zip file path.
- target_dir (str or Path) – target path to be save the unzipped files.
-
beta_rec.utils.common_util.update_args(config, args)[source]¶ Update config parameters by the received parameters from command line.
Parameters: - config (dict) – Initial dict of the parameters from JSON config file.
- args (object) – An argparse Argument object with attributes being the parameters to be updated.
beta_rec.utils.constants module¶
beta_rec.utils.download module¶
-
beta_rec.utils.download.download_file(url, store_file_path)[source]¶ Download the raw dataset file.
Download the dataset with the given url and save to the store_path.
Parameters: - url – the url that can be downloaded the dataset file.
- store_file_path – the path that stores the downloaded file.
Returns: the archive format of the suffix.
beta_rec.utils.evaluation module¶
-
class
beta_rec.utils.evaluation.PandasHash(pandas_object)[source]¶ Bases:
objectWrapper class to allow pandas objects (DataFrames or Series) to be hashable.
-
pandas_object¶
-
-
beta_rec.utils.evaluation.auc(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction')[source]¶ Calculate the Area-Under-Curve metric.
Calculate the Aread-Under-Curve metric for implicit feedback typed recommender, where rating is binary and prediction is float number ranging from 0 to 1.
https://en.wikipedia.org/wiki/Receiver_operating_characteristic#Area_under_the_curve
Note
The evaluation does not require a leave-one-out scenario. This metric does not calculate group-based AUC which considers the AUC scores averaged across users. It is also not limited to k. Instead, it calculates the scores on the entire prediction results regardless the users.
Parameters: - rating_true (pd.DataFrame) – True data.
- rating_pred (pd.DataFrame) – Predicted data.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
Returns: auc_score (min=0, max=1).
Return type: float
-
beta_rec.utils.evaluation.check_column_dtypes(func)[source]¶ Check columns of DataFrame inputs.
- This includes the checks on
- whether the input columns exist in the input DataFrames.
- whether the data types of col_user as well as col_item are matched in the two input DataFrames.
Parameters: func (function) – function that will be wrapped.
-
beta_rec.utils.evaluation.exp_var(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction')[source]¶ Calculate explained variance.
Parameters: - rating_true (pd.DataFrame) – True data. There should be no duplicate (userID, itemID) pairs.
- rating_pred (pd.DataFrame) – Predicted data. There should be no duplicate (userID, itemID) pairs.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
Returns: Explained variance (min=0, max=1).
Return type: float
-
beta_rec.utils.evaluation.get_top_k_items(dataframe, col_user='col_user', col_rating='col_rating', k=10)[source]¶ Get the input customer-item-rating tuple in the format of Pandas.
DataFrame, output a Pandas DataFrame in the dense format of top k items for each user.
Note
if it is implicit rating, just append a column of constants to be ratings.
Parameters: - dataframe (pandas.DataFrame) – DataFrame of rating data (in the format
- customerID-itemID-rating) –
- col_user (str) – column name for user.
- col_rating (str) – column name for rating.
- k (int) – number of items for each user.
Returns: DataFrame of top k items for each user.
Return type: pd.DataFrame
-
beta_rec.utils.evaluation.has_columns(df, columns)[source]¶ Check if DataFrame has necessary columns.
Parameters: - df (pd.DataFrame) – DataFrame.
- columns (list(str) – columns to check for.
Returns: True if DataFrame has specified columns.
Return type: bool
-
beta_rec.utils.evaluation.has_same_base_dtype(df_1, df_2, columns=None)[source]¶ Check if specified columns have the same base dtypes across both DataFrames.
Parameters: - df_1 (pd.DataFrame) – first DataFrame.
- df_2 (pd.DataFrame) – second DataFrame.
- columns (list(str)) – columns to check, None checks all columns.
Returns: True if DataFrames columns have the same base dtypes.
Return type: bool
-
beta_rec.utils.evaluation.logloss(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction')[source]¶ Calculate the logloss metric.
Calculate the logloss metric for implicit feedback typed recommender, where rating is binary and prediction is float number ranging from 0 to 1.
https://en.wikipedia.org/wiki/Loss_functions_for_classification#Cross_entropy_loss_(Log_Loss)
Parameters: - rating_true (pd.DataFrame) – True data.
- rating_pred (pd.DataFrame) – Predicted data.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
Returns: log_loss_score (min=-inf, max=inf).
Return type: float
-
beta_rec.utils.evaluation.lru_cache_df(maxsize, typed=False)[source]¶ Least-recently-used cache decorator.
Parameters: - maxsize (int|None) – max size of cache, if set to None cache is boundless.
- typed (bool) – arguments of different types are cached separately.
-
beta_rec.utils.evaluation.mae(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction')[source]¶ Calculate Mean Absolute Error.
Parameters: - rating_true (pd.DataFrame) – True data. There should be no duplicate (userID, itemID) pairs.
- rating_pred (pd.DataFrame) – Predicted data. There should be no duplicate (userID, itemID) pairs.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
Returns: Mean Absolute Error.
Return type: float
-
beta_rec.utils.evaluation.map_at_k(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction', relevancy_method='top_k', k=10, threshold=10)[source]¶ Mean Average Precision at k.
The implementation of MAP is referenced from Spark MLlib evaluation metrics. https://spark.apache.org/docs/2.3.0/mllib-evaluation-metrics.html#ranking-systems
A good reference can be found at: http://web.stanford.edu/class/cs276/handouts/EvaluationNew-handout-6-per.pdf
Note
1. The evaluation function is named as ‘MAP is at k’ because the evaluation class takes top k items for the prediction items. The naming is different from Spark. 2. The MAP is meant to calculate Avg. Precision for the relevant items, so it is normalized by the number of relevant items in the ground truth data, instead of k.
Parameters: - rating_true (pd.DataFrame) – True DataFrame.
- rating_pred (pd.DataFrame) – Predicted DataFrame.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
- relevancy_method (str) – method for determining relevancy [‘top_k’, ‘by_threshold’].
- k (int) – number of top k items per user.
- threshold (float) – threshold of top items per user (optional).
Returns: MAP at k (min=0, max=1).
Return type: float
-
beta_rec.utils.evaluation.merge_ranking_true_pred(rating_true, rating_pred, col_user, col_item, col_rating, col_prediction, relevancy_method, k=10, threshold=10)[source]¶ Filter truth and prediction data frames on common users.
Parameters: - rating_true (pd.DataFrame) – True DataFrame.
- rating_pred (pd.DataFrame) – Predicted DataFrame.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
- relevancy_method (str) – method for determining relevancy [‘top_k’, ‘by_threshold’].
- k (int) – number of top k items per user (optional).
- threshold (float) – threshold of top items per user (optional).
Returns: DataFrame of recommendation hits DataFrmae of hit counts vs actual relevant items per user number of unique user ids.
Return type: pd.DataFrame, pd.DataFrame, int
-
beta_rec.utils.evaluation.merge_rating_true_pred(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction')[source]¶ Join truth and prediction data frames on userID and itemID.
Joint truth and prediction DataFrames on userID and itemID and return the true and predicted rated with the correct index.
Parameters: - rating_true (pd.DataFrame) – True data.
- rating_pred (pd.DataFrame) – Predicted data.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
Returns: Array with the true ratings. np.array: Array with the predicted ratings.
Return type: np.array
-
beta_rec.utils.evaluation.ndcg_at_k(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction', relevancy_method='top_k', k=10, threshold=10)[source]¶ Compute Normalized Discounted Cumulative Gain (nDCG).
Info: https://en.wikipedia.org/wiki/Discounted_cumulative_gain
Parameters: - rating_true (pd.DataFrame) – True DataFrame.
- rating_pred (pd.DataFrame) – Predicted DataFrame.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
- relevancy_method (str) – method for determining relevancy [‘top_k’, ‘by_threshold’].
- k (int) – number of top k items per user.
- threshold (float) – threshold of top items per user (optional).
Returns: nDCG at k (min=0, max=1).
Return type: float
-
beta_rec.utils.evaluation.precision_at_k(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction', relevancy_method='top_k', k=10, threshold=10)[source]¶ Precision at K.
Note: We use the same formula to calculate precision@k as that in Spark. More details can be found at http://spark.apache.org/docs/2.1.1/api/python/pyspark.mllib.html#pyspark.mllib.evaluation.RankingMetrics.precisionAt In particular, the maximum achievable precision may be < 1, if the number of items for a user in rating_pred is less than k.
Parameters: - rating_true (pd.DataFrame) – True DataFrame.
- rating_pred (pd.DataFrame) – Predicted DataFrame.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
- relevancy_method (str) – method for determining relevancy [‘top_k’, ‘by_threshold’].
- k (int) – number of top k items per user.
- threshold (float) – threshold of top items per user (optional).
Returns: precision at k (min=0, max=1).
Return type: float
-
beta_rec.utils.evaluation.recall_at_k(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction', relevancy_method='top_k', k=10, threshold=10)[source]¶ Recall at K.
Parameters: - rating_true (pd.DataFrame) – True DataFrame.
- rating_pred (pd.DataFrame) – Predicted DataFrame.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
- relevancy_method (str) – method for determining relevancy [‘top_k’, ‘by_threshold’].
- k (int) – number of top k items per user.
- threshold (float) – threshold of top items per user (optional).
Returns: - recall at k (min=0, max=1). The maximum value is 1 even when fewer than
k items exist for a user in rating_true.
Return type: float
-
beta_rec.utils.evaluation.rmse(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction')[source]¶ Calculate Root Mean Squared Error.
Parameters: - rating_true (pd.DataFrame) – True data. There should be no duplicate (userID, itemID) pairs.
- rating_pred (pd.DataFrame) – Predicted data. There should be no duplicate (userID, itemID) pairs.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
Returns: Root mean squared error.
Return type: float
-
beta_rec.utils.evaluation.rsquared(rating_true, rating_pred, col_user='col_user', col_item='col_item', col_rating='col_rating', col_prediction='col_prediction')[source]¶ Calculate R squared.
Parameters: - rating_true (pd.DataFrame) – True data. There should be no duplicate (userID, itemID) pairs.
- rating_pred (pd.DataFrame) – Predicted data. There should be no duplicate (userID, itemID) pairs.
- col_user (str) – column name for user.
- col_item (str) – column name for item.
- col_rating (str) – column name for rating.
- col_prediction (str) – column name for prediction.
Returns: R squared (min=0, max=1).
Return type: float
beta_rec.utils.logger module¶
-
class
beta_rec.utils.logger.Logger(filename='default', stdout=None, stderr=None)[source]¶ Bases:
objectLogger Class.
beta_rec.utils.monitor module¶
beta_rec.utils.onedrive module¶
-
class
beta_rec.utils.onedrive.OneDrive(url=None, path=None)[source]¶ Bases:
objectDownload shared file/folder to localhost with persisted structure.
Download shared file/folder from OneDrive without authentication.
params: str:url: url to the shared one drive folder or file str:path: local filesystem path
methods: download() -> None: fire async download of all files found in URL
beta_rec.utils.seq_evaluation module¶
-
beta_rec.utils.seq_evaluation.count_a_in_b_unique(a, b)[source]¶ Count unique items.
Parameters: - a (List) – list of lists.
- b (List) – list of lists.
Returns: number of elements of a in b.
Return type: count (int)
-
beta_rec.utils.seq_evaluation.mrr(ground_truth, prediction)[source]¶ Compute Mean Reciprocal Rank metric. Reciprocal Rank is set 0 if no predicted item is in contained the ground truth.
Parameters: - ground_truth (List) – the ground truth set or sequence
- prediction (List) – the predicted set or sequence
Returns: the value of the metric
Return type: rr (float)
-
beta_rec.utils.seq_evaluation.ndcg(ground_truth, prediction)[source]¶ Compute Normalized Discounted Cumulative Gain (NDCG) metric.
Parameters: - ground_truth (List) – the ground truth set or sequence.
- prediction (List) – the predicted set or sequence.
Returns: the value of the metric.
Return type: ndcg (float)
-
beta_rec.utils.seq_evaluation.precision(ground_truth, prediction)[source]¶ Compute Precision metric.
Parameters: - ground_truth (List) – the ground truth set or sequence
- prediction (List) – the predicted set or sequence
Returns: the value of the metric
Return type: precision_score (float)
beta_rec.utils.triple_sampler module¶
beta_rec.utils.unigram_table module¶
Module contents¶
Utils Module.
Standardization of Code Format and Documentation¶
Author: Junhua Liang, Yucheng Liang
Last Updated: 2020-06-14
Goal¶
The goal of this project is to build a flexible framework and unified interfaces for recommender systems (RecSys), with which all the RecSys practitioner and researchers are able to 1) test/evaluate existing models and 2) build/modify their own new models easily. Hence, the code readability is extremely critical. Our team is keen on keeping a nice, clean and documented code so that every single file can be understood by other researchers and developers. Therefore, shall we suggest those ,who would like to contribute to this project to follow the designed format. Indeed, those Pull requests, which do not follow the format can not pass the our CI test. We use black-formatter, flake8-docstrings and isort to format our code.
In addition, we try to maintain informative documentation, which requires a formatted comment style in codes. Stacking everything into documentation is quite easy, but clear, formatted documentation will be more helpful, and that’s what we want to achieve.
Consequently, in this documentation, some rules are listed in order to keep developers writing codes properly. And we hope every contributor is supposed to observe these standards.
Python Coding and Docstrings Style¶
We use the automatic style formatter Black. See the installation guide for VSCode and PyCharm. Black supersets the well-known style guide PEP 8, defined by Guido van Rossum and collaborators. PEP 8 defines everything from naming conventions, indentation guidelines, block vs inline comments, how to use trailing commas and so on.
We use Google style for formatting the docstrings.
- Black formatting on Python files.
- Black formatting on Notebooks.
- Docstring with Google style.
- Isort to sort imports alphabetically, and automatically separated into sections.
If you are using Pycharm, it will be convenient to deploy black and isort commands as External Tools.
**Use the following args to make it compatible with black. **
isort --multi-line=3 --trailing-comma --force-grid-wrap=0 --use-parentheses --line-width=88 [ file.py ]
Or directly apply the default config file in our project root folder.
[settings]
line_length=88
indent=' '
multi_line_output=3
include_trailing_comma=true
use_parentheses=true
force_grid_wrap=0
Also, as jupyter notebook is widely used by most researchers, we are suppposed to ensure the codes in notebook also follow our code style. So we use flake8_nb to check your notebook. Be careful when you black your notebook. Because black can only format code in *.py file, it may cause terrible problem if you use black to format a notebook.** We strongly suggest that you should use black_nbconvert to format your notebook safely.**
The following examples are part of demo.py. For complete usages, please refer to demo.py.
Class¶
This is an example of how to write comments on a class.
r"""This document is a demo."""
class NoteDemo(object):
r"""A class used to sort an unsorted array with a different kind of algorithm.
Including quick-sort, merge-sort, shell-sort, etc. Please refer to :class:`NoteDemo`
for more details.
.. note::
If you want to let the user switch to a specific class, please add :class:`class-name`
.. math::
a^{2} + b^{2} = c{^2}
If you want to use the unordered list, try as follows:
* :attr:`a`: first params.
* :attr:`b`: second params.
Class information...
Class information...
Attributes:
init_array: unsorted array, :math:`\sum_{i=0}^{n}a_i` is inline math example.
"""
def __init__(self, init_array):
r"""Init the demo class."""
self.array = init_array
- Introduction and Summary: The first line of comments should be the introduction, which is ended with a period. And after a new line, you should write the details of this class, which is also ended with a period.
- Note block: If you want to note something or write some warnings, you should use the block.
- Attributes: All the class variables should be written here. So there is no need for you to write the arguments of
initmethods.
Method¶
def return_function(self, param1, param2):
r"""Show how to write notes correctly.
I will show math, example, yield in this function.
Please follow this standard to write your code.
.. note::
If you want to write some note, please add `Note:`
as this example.
Example:
>>> demo = NoteDemo([1, 2, 3, 4])
... demo.return_function("Hello", true)
Args:
param1 (str): string type parameter example.
param2 (bool): bool type parameter example.
Returns:
bool: True if yes, False if no.
Raises:
ValueError: param1 is not a string
"""
pass
- Introduction and Summary: The first line of comments should be the introduction, which is ended with a period. And after a new line, you should write the details of this method, which is also ended with a period.
- Args: You should detail each parameter here, writing their names, types and meaning.
- Returns: You should detail each return values here, writing their types and meaning. For more than one return value, please refer to the next part.
- Raise: If this method raises an exception, you should write them in this part.
def yield_function(self, param1, param2):
r"""Show how to write notes when you are ready to write a function with yield.
Please follow this standard to finish your code.
Args:
param1 (int): int type parameter
param2 (list): list tpye parameter
Returns:
(bool, int): a tuple with bool and int types.
Yields:
(string, torch. Tensor): Tuple containing a string type and a tensor type.
"""
pass
Returns: If the method returns more than one value, you should first write their types in a bracket, and then detail them.
Yields: Returns some iterators, you should write in this part.
Example Block¶
Example:
>>> demo = NoteDemo([1, 2, 3, 4])
... demo.return_function("Hello", true)
- If you want to give some example of how to use this method, this is a way for you to share.
Math Block¶
.. math::
a^{2} + b^{2} = c{^2}
- If the method has some mathematical background, you can use a math block to provide some information.
Jump to a class definition¶
If you want to link a class to its definition in comments, you can write comments like the following:
 Jump to a class definition
Jump to a class definition
Return Type¶
There are many ways to write returns. Just choose one of them and clarify the values and types.
 return type1
return type1
 return type2
return type2
Format Check¶
As we want to provide good documentation, we hope to use some tools to maintain our quality of comments. In general, we use pydocstyle to check our code in CI. If your code fails to meet the requirements of such a check, your PR will not be approved.
Special Cases¶
In this part, we try to collect
1. Indention¶
There should be no space between the first letter and the """ in the first line of comment. And the first character should use uppercase.
| Code Example | Documentation |
|---|---|
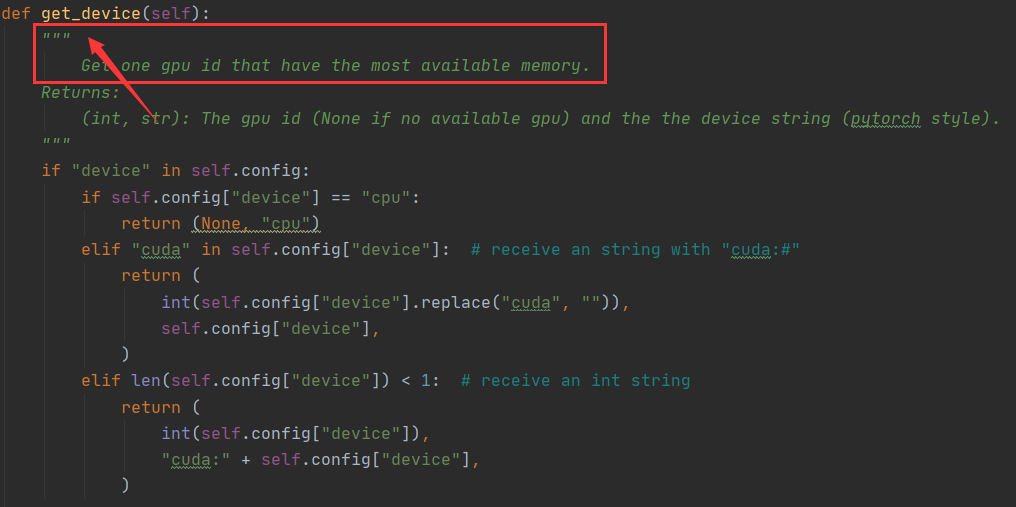 |
 |
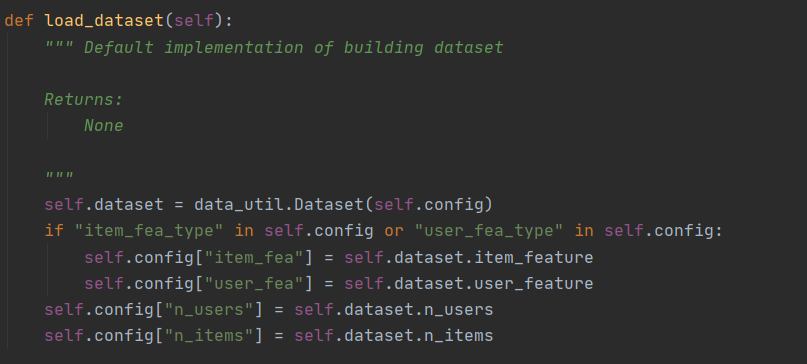 |
 |
2. Newlines¶
There should be a new line between summary and details in a comment block. But in the detail part, there should be no newline.
| Code Example | Documentation |
|---|---|
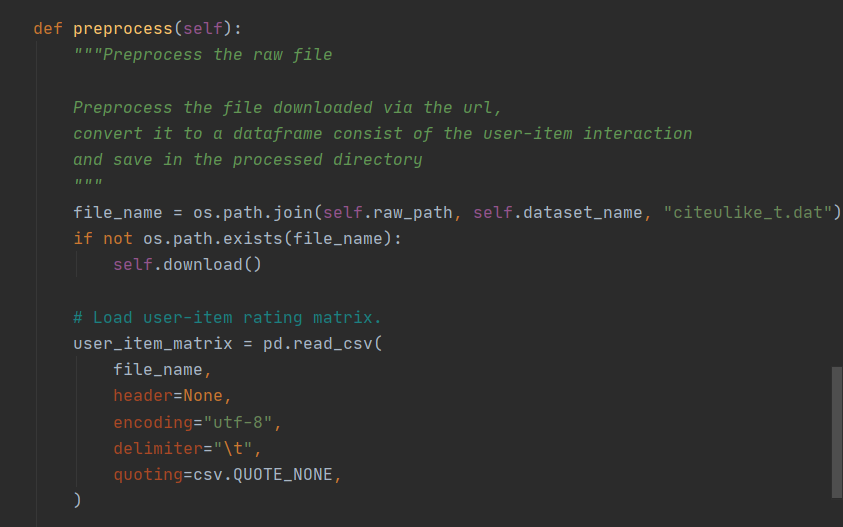 |
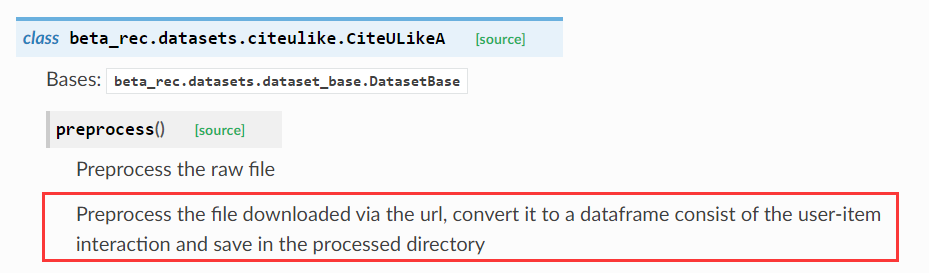 |
Action Item¶
- [x] Correct all typos in code, including code and comments.
- [x] Correct all naming that do not match the naming rules.
- [x] Format all comments, adding usage example, more informative description etc.